What data can you get using Twitter scraper?
What important information can be extracted by web scraping Twitter? Which methods of Twitter web data scraping are used? Parsing difficulties.
Each message on this social network is limited by 280 characters, but the number of tweets published daily is still growing and according to the latest research exceeds 500 million (Mention, 2018). From this huge pool of data you can for sure get some treasures of information depending on what exactly you are looking for.
What important information can be extracted by web scraping Twitter?
Here are some examples:
- Use tags search to get the actual public opinion and today’s trends in discussions. If you are a sociologist, politician, journalist or just a video blogger who tries to get hype – it should be your main source of scrapping.
- Twitter is a source of news. Want to get closer to high society life of celebrities or to gather all the latest quotes of opinion leaders or businessmen? Just make a list of profiles that are important to you for any reason – include, say, Kit Harington and Emilia Clarke’s profiles or your business competitors’ profiles – and scrape Twitter data from them. It could be faster and more comprehensive than scrolling your news feed manually.

- For social media marketing specialists every account is a particle of an audience in itself. And popular accounts can even play the role of an advertising platform. 67% of B2B companies use this social network as one of their marketing tools (Statista, 2018), so web scraping Twitter to get in touch with one’s target audience really makes sense for marketers nowadays. Another marketing point is parsing and measuring tweets statistics (likes, retweets) for a better understanding of the conversion and involvement of the audience.
- Although only 4 images or one video can be attached to a tweet, Twitter is the source of quality and unique text and media content. Vast majority of Internet users consume social media content and just a small part of them is rightfully considered to be content creators. Many platforms and communities just copy, aggregate and filter materials found on a third party’s Internet resources. Some fresh tweet with a funny quote or picture is forced to travel far beyond Twitter – and it is possible thanks to one of the tweet scraper tools.
- Finally, Twitter scraper is very handy when you need to collect a contact database. One active link is usually placed in every profile – official site with some probability. Also some users write down their date of birth and current geographic location. For those who understand the Internet sales techniques this information must be very precious.
We could continue this list because it is impossible to name all the uses relating to web scraping Twitter. Talking about the most exotic reason for data parsing let’s speak about data crawling profiles in order to add all avatar pictures to a face recognition database. Consider this a joke. Or maybe not.
Which methods of Twitter web data scraping are used?
Using Twitter API is unfortunately impossible. Social network has the official API with wrappers for JavaScript (Node.js), Python and Ruby, and a lot of communities developed clients for other programming languages like C++, Java, PHP, Go, Haskell etc.
But for most parsing tasks it is not allowed to use API –you will find more details on that in the next section of this article – so we can’t talk about scraper API as one of legal and easy methods of data extraction, in spite of the fact that most open source scrapers for Twitter use its API and require API keys.
Here are some examples of projects on Python using official Twitter API:
- Tweepy – the most popular tool for interacting with Twitter;
- Twython – supports normal and streaming APIs;
- Twitter Scrape – allows you to search tweets by keywords and dump them into a file;
- Tweets Analyzer – module to scrape Twitter data (metadata) andto analyze tweet activity.
And the exception – one Python based Twitter scraper that does NOT require official API keys:
- Twitter Scraper – breaks the borders and limits of scraping simply by using Selenium.
But even the choice to use Selenium has some hidden difficulties (we will also get closer to them further).

Another way to extract data is to use one of the web scraping Twitter services:
- Octoparse – is a general purpose scraper for data extraction on the web You will find a relevant case by clicking here.
- Twitter Scraper from Scraping Expert – a web based scraper for parsing profiles, tweets and followers.
Ready-to-use web services are good for non-programmers, because you don’t need to write any code to use them. But anyway you have to use them wisely and carefully as you provide them your Twitter profile information. You may be easily blocked by Twitter for repeated automated actions.
What kind of difficulties can I face?
All the issues of scraping can be divided into API difficulties and common parsing difficulties.
API access difficulties
Besides the common limitations of request number or the volume of received data, Twitter has one unpleasant feature. You have to apply and receive approval for a developer account (here) before you get your application key and API token for using any API methods. In other words the social network wants you to explain in details how and what you will use the API for, and if you don’t want to get refused you should carefully read about restricted uses of the Twitter APIs.
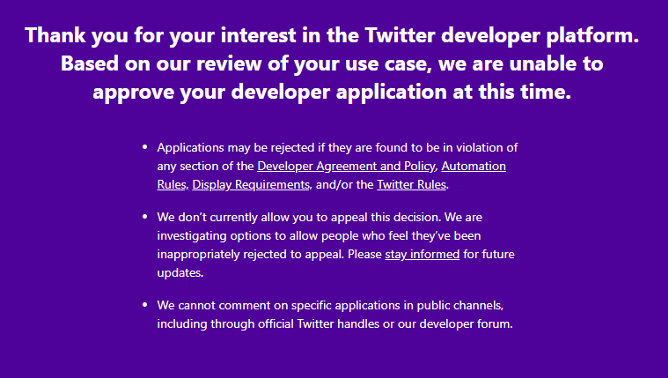
Remember! Once your access has been rejected, you will not a the second chance to reapply for it!
Restricted API use cases concern the protection of users’ personal data, content redistribution, calculating any user metrics and many more. As you see writing a scrapper via official API is a risky idea.
Parsing difficulties
Every time you send the GET request to the social network’s home page you get a limited number of records and see no pagination block in the bottom of the page or elsewhere. Next chunk of posts loads during scrolling down the page – this behavior is managed by JavaScript. It means that a simple HTTP-client and some tools and libraries for HTML parsing are not good for web scraping Twitter, no matter what programming language you use.
Therefore you need a tool to control the browser instance (Selenium + Phantom JS, to name some) to call the scroll down event and activate the related JS code for loading a new portion of tweets. Imagine your script is crawling among 1000 profiles with 5000 tweets inside each profile and for some reason it has been stopped somewhere in the middle and now it starts from the beginning. Finally it finds the right profile on which it was interrupted last time and scrolls down all the tweets from the top of the page again before it gets to the first unparsed tweet.
It seems that scrolling down is the only decision and it is extremely slow.
A smaller problem is to pass the social network authentication data with your automated browser – but it comes down to the right waiting intervals and using send keys method for the fields of the form.
Summary
Billions of short tweets keep inside the data relating to any possible spheres of interest and some of us are no longer satisfied with simply going through our news feed. We use web scraping tools and scrapers to deal with data and find the ways to get information we need in spite of protection methods and closed API.