Web crawling VS Web scraping
The key differences between web scraping and web crawling. Functions of web scraping and web crawling.
In the modern era of data operations, analyzing big data and getting relevant information from huge data seems impracticable. Web crawling and web scraping are two techniques that made it easier for analysts as well as non-programmers to retrieve information and get advantage of it. In this article we will talk more about what is web scraping and crawling.

Web crawling:
The terms of web crawling vs web scraping are closely interlinked but there are major differences between them. Web crawling is the term used to scan the data on the web through a crawler called “spider” also called crawl agent or bot. A crawler goes deeper into the web pages and do search function for the relevant content. The spider or crawler is programmed in a way that it can aimlessly navigate and explore the search engine site or a web and can get itself what the site is offering. A web crawler can fetch the web links and direct the user to retrieve information without hustle.
Web scraping:
On the other hand, web scraping (also called web harvesting, web data extraction and screen scrapping) is the process of extracting structured data not just from anywhere on the web, but it can be generally from a database or a machine. A web scraper target specific sites or pages and retrieve specific information. The data can be saved, copied, formatted and stored in a database through web scrapper, but not from web crawling. Web scraping can be done manually, but mostly scraping tools and scraping software are preferred for ease of use and fast results. Just as websites, appear in many forms so as web scrapers for better functionality of extraction and exploration.
The key differences of web crawling vs web scraping.
| web scraping | web crawling |
| Process of Extraction of data from various sources. i-e web, computer, etc. | Process of data extraction, particularly from the web |
| De-duplication is not involved, as it does not extract duplicate data. Hence more reliable | De-duplication is involved and can’t be overcome by any mean |
| Can be done by scraping/crawl agents and scrapers and parsers. | Only crawl agents are needed. |
| It can be done at small as well as large scale | It is used mostly at large scale with huge database. |
These two processes do a wide range of an extract data search, but web scraping is more focused, relevant and useful, as it gets data from a specific source and makes the user use it in their own ways by innovating it.
Functions of Web crawling:
Now when we discussed what is web crawling and scraping, let’s talk about their functions. Web crawling specifically used to generate a copy of all web pages visited by a user on the search engine for later use. A crawler or spider can also be used for checking links, maintaining web tasks automatically and validation purposes. Web crawler do indexing of the site on the web, so that they may appear in a search engine when users search for a relevant site.
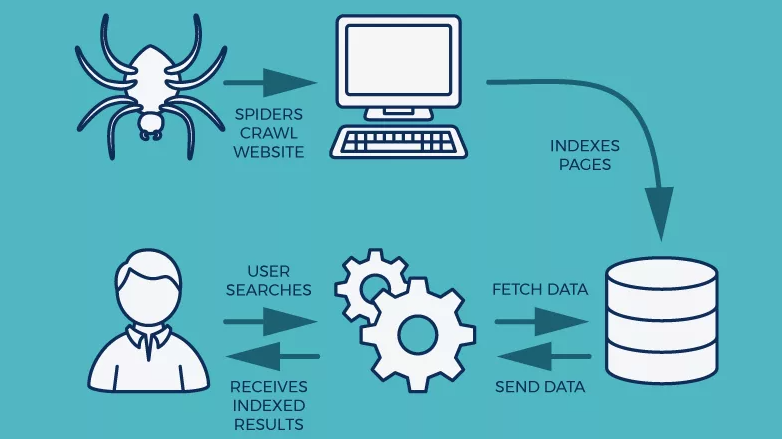
Web crawler mainly provides:
- Data accessibility
- Indexation of data
- Tag managers
- Google analytics
- Linking the data
- Unlisted and listed URLS data
- Text, images and codes.
Once a user types the specific search words, the web crawler has the function of scanning all pages, and find those having keywords, and can turn them into huge index. For example, if you are doing a search using Google search engine, the crawler would perform the function of exploring each of the indexed pages in Google database, and extract them to serve. It follows hyperlinks and visit other web pages as well.
Functions of Web scraping:
Web scraping can be done at a small, as well as at large scale; so many industries, as well as small businesses, even individuals are taking advantage of this data extraction technique. On different levels web scraping also usually hits structured data.
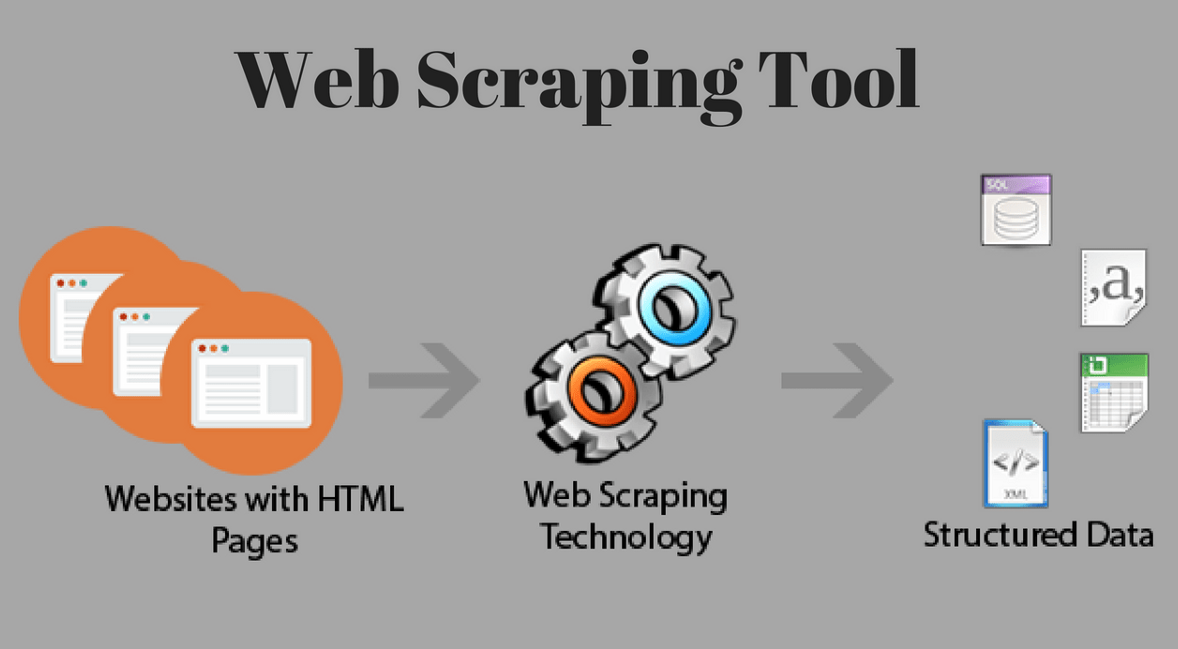
It performs the function of:
- Collection of information as company names,
- Comparison among prices,
- Get product details,
- Monitor competition,
- Collecting emails, phone numbers and URLs.
- Scraping statistics of sports and leagues for betting and other purposes
- Scraping of site data before the website migration
- Scraping financial information and analysis reports for research purposes and getting insights of the market.
- Scraping contact information from yellow pages to generate leads
It can also extract property, as well as property agent details for contacts on real state websites. The main function that web scraping performs, is that data can be stored in a database for future use. On structured and poorly organized data can be fetched by web scraping and the user can convert it into a structured, useable format like in excel spreadsheets or CSV files.
Web scraper can automate the data extraction in a fast and efficient way, no matter how large the data is on the web or on the computer. Scraper can extract data and can copy or save it to a local file on the system.
Web scrapers come in two forms as a browser extension and computer software. Both of these tools function for simple use and integrate purposeful information.
Examples of scrapers and crawlers:
Examples of Web crawlers:
The most popular and well-known web crawler now a days is GOOGLE BOT. Google bot is used nowadays to index sites from Google’s search engine.
Other widely used web crawlers are:
- BINGBOT
- SLURP BOT (REPLACEMENT FOR MSN BOT)
- DUCKDUCKBOT
- BAIDUSPIDER
- YANDEX BOT
- SOGOU SPIDER
- EXABOT
Examples of Web scraper:
There are various web scrapers available to retrieve helpful and relevant information. However, in the beginning, it was not the same case as users used to store the information, by copying it into excel or other apps, just because some websites don’t provide API (application programming interface) and any option to store data. One of the most well-known web scraper for social media is OCTOPARSE; it was developed for non-coders. OCTOPARSE Cloud Extraction (paid plan) works well for getting dynamic data feeds, as it supports the extraction schedule as frequently as every 1 min.
Now developers have got personalized scrapers, that run on their own servers like APIFY, SCRAPY and BEAUTIFUL SOUP, which simplified the work. For non-developers, there are point and click web scrapers, which do web scraping manually as DEXI, it is good for simpler and smaller projects and scraping.
In concluding remarks, scraping is an ultimate superficial node of crawling. One have to do crawling at any level, before going for scrapping, for better and remarkable results.