Twitter sentiment analysis – what people think about your brand
Sentiment analysis is an automated process of extraction and analyzing data considering customers’ expectations, preferences and aversions from natural language texts – reviews, blogs or social media records
Twitter sentiment analysis gives companies a better understanding of what people think about their brand, service, product features or any particular topic.
We have already discussed how to create a crawler and scrape Twitter data previously, now it’s time to talk about utilization and drawing conclusions from the data.
During Twitter sentiment analysis (opinion mining) all gathered tweets (opinions) are being classifyed as Positive, Negative or Neutral. It is called Polarity Detection. The rating scale can be supplemented with Very negative and Very positive or even transformed into numerical estimatiton from 1 to 5, from 1 to 10 etc., where the highest number corresponds to the highest positive emotion.
For example, Tesla Company is promoting Solar Roofs for houses now, and here is one of the comments relating to this topic on Twitter:
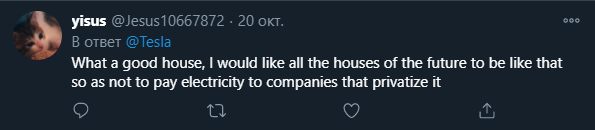
We can manually read, understand and interpret the mood of this text as Positive or we can use the tools of automated text analysis to make our computer do this job for us. Discarding special cases with emotionally complex or sarcastic tweets, machine can classify statements with a high degree of accuracy. Let’s make a test.
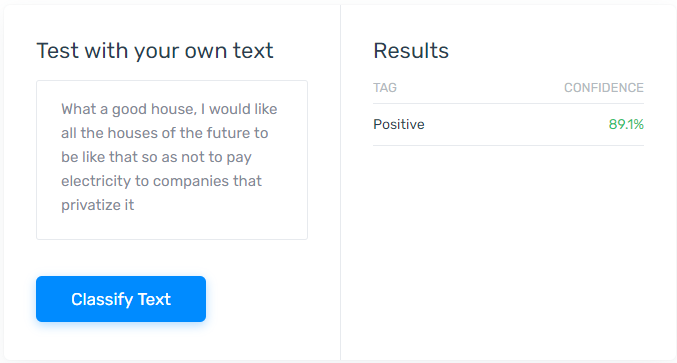
This result is achieved by the a method called Natural Language Processing (NLP), based on two main algorithms:
- Rule-based sentiment analysis – strict rules define the result. To put it simply, iIf text contains words and phrases describing anger (“kill”, “bad”, “damn”), the message is Negative. The difficulty is that with such words we can express positive emotions too (“it was damn good” or “this product is bad ass!”). The same we can noticecan noticed for about the words and phrases usually describing happiness.
- Automatic machine learning techniques – computer learns from big data and after training its neural network copes with the emotion analysis issue.
In the modern text processing software both algorithms are combined to achieve the higher accuracy.
Twitter sentiment analysis Python code
Examples of Python code for sentiment analysis Twitter are based on packages for web scraping, natural language processing, data-science and data visualization.
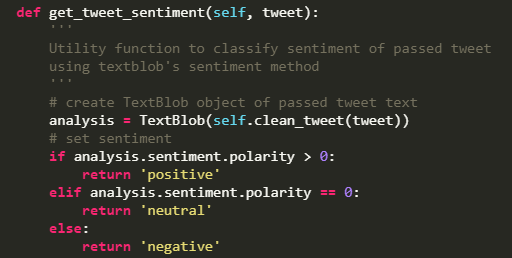
The minimum required functionality is covered by tweepy and textblob. You will need to receive API keys and access tokens before using tweepy, the most popular Twitter API wrapper for Python. Then get tweets with tweepy and clean text from unwanted characters with regular expressions.
Textbloob already has built-in methods for sentence polarity detection:
from textblob import TextBlob
blob = TextBlob(tweet_text_here)
print(blob.sentiment.polarity)
This example will print out text polarity value. Based on the value we get the following conclusions about a tweet:
- Greater than 0 – positive;
- Equals to 0 – neutral;
- Less than 0 – negative.
Full code with only tweepy and textblob supplemented with detailed explanations can be found here.
Extended functionality requires a bunch of Python packages:
- pandas – for building data frames and making work with tweets dataset more convenient;
- wordcloud – for plotting word clouds and visualizing frequency of words within a text;
- matplotlib – for creating a scatter plot that shows how tweets are ranked by polarity.
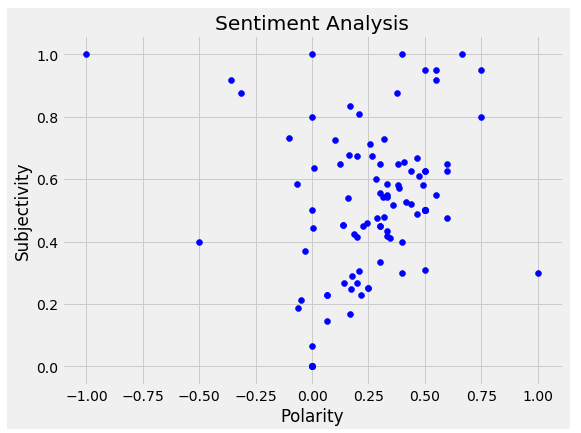
In addition to polarity it would be nice to calculate subjectivity for every tweet. Subjectivity describes how strong the personal opinion, emotion or judgment is represented in a text. Subjective statements are significant for our research, because we rather want to deal with specific private opinions than some abstract tweets. Textblob has sentiment.subjectivity method that returns a float number between 0 and 1 representing a value of subjectivity.
An interesting example code with extended functionality and visualization for Twitter sentiment analysis Python can be found at this link. If you are searching for an expert-level approach to data analytics, read articles on Kaggle, e.g., this one by Paolo Ripamonti.
Tools for sentiment analysis of twitter data
Ready to use tools for sentiment analysis of Twitter data solve the whole range of tasks from data mining to a qualitative presentation of the results. Let’s take a quick look at some of them.
- Mediatoolkit – a powerful social media monitoring application, offering you real-time mention tracking with nice-looking sentiment reports. As the official site promises, Mediatoolkit supports any language in the World and works with Twitter, Instagram, Facebook, YouTube and other social networks. It will let you know how people are talking about your brand or product. The simplest Mediatoolkit pricing plan starts from 99 Euro per month.
- MonkeyLearn – a tool for text analysis based on machine learning algorithms. The official site describes it as an easy-to-use platform, but we can hardly agree with this statement. Twitter data parsing and preparation proceeds with a third party’s tools (Export Tweet, Tweet Download and others). Creating a sentiment analysis model requires a special tutorial – you have to know how to create and train your model. MonkeyLearn would be a good solution if you already have the data readily available, or if you are a Python programmer and able to use MonkeyLearn API for machine learning sentiment analysis. MonkeyLearn Studio prices start from 500$ per month and the API costs 239$ per month.
- Brand24 – a social media monitoring tool to analyze sentiment on Twitter. The official site states that the tool is based on the most recent machine learning algorithms, understands more than 90 languages and works with human-like accuracy. While launching a new mobile application, Uber – a worldwide popular taxi service – used Brand24 to get a quick feedback about the app and to find some insights from the audience. Pricing plans of Brand24 start from 49$ per month.
An informed choice of Twitter sentiment analysis tool is possible if you understand its methods and algorithms and can clearly articulate its purposes for your business.