Professional LLM Tools
How to integrate large language models into software products. From prompts, libraries and APIs to LLM frameworks and monitoring.

Transformer-based Large Language Models (LLMs), such as ChatGPT and Claude, show impressive results in natural language processing tasks. However, integrating LLMs into proprietary software solutions requires specialized knowledge and skills.
Below we will look at how to use the features of large language models in your own software products:
- how to correctly formulate queries (prompts) for models to get answers that can be used in your own software;
- How to integrate models using APIs;
- how to optimize the performance of models for specific application tasks;
- How to assess the quality of models and select appropriate results;
- how to combine the capabilities of different models to solve complex problems.
The art of working with prompts
The basis of work with dialog LLM is a prompt - a request that the user addresses to the neural network. In this case, the quality of the transmitted information significantly affects the result obtained.
If working with prompts is new to you, start with the Learn Prompting course – it's a great resource to learn how to write high-quality queries for neural networks. If you don't have time to take the course yet, the following formula can significantly improve your results:
Ideal Prompt = Purpose + Context + Role + Constraint + Examples
Purpose is the desired result that the model should produce, e.g. "propose a marketing campaign plan for a startup". Context is necessary background information for solving the problem: the more detailed, the better. Role is a conditional person on whose behalf the model should compose the text. For example, "answer as a lawyer specializing in corporate law". Constraint is any framework for the content to be given out: the volume of text, style of presentation, prohibition of topics, etc. With the help of Examples, you can suggest to the model the format of the output, which will need to be parsed further.
Since a prompt is a kind of interface to the LLM, users often use some template that is dynamically augmented for a specific task. Therefore, one of the first important early additions to the LLM were tools for prompt enrichment, storage and categorization.
Search. It is worth noting that the topic of prompt creation is especially specific to content generation tasks, where prompt marketplaces have already been formed. For example, on Prompt Base and Snack Prompt users can view, for example, samples of generated images and purchase a prompt.
There are also free libraries of successful role descriptions: for example, Awesome ChatGPT Prompts or embedded in HyperWrite service. And FlowGPT service is a search engine for prompts for various tasks: academic prompts, software development, startups, etc. There are also extensions for browsers: PromptPlus, DashAI and Promptheus.
Enhancement. Instead of looking for ready-made Prompts and their enhancers, you can enhance your own Prompt - use What a Prompt or Promptify. For developers, Cohere will be especially interesting: the tool makes an enhancement of a user's request and allows you to embed the generated result into program code in Python, Go, JavaScript, send it to the Curl utility or output it via the terminal.
Storage. Once you've worked with LLM, you'll probably want to store your Prompts collection somewhere, for example, in Readmo or Beamcast. TypingMind not only contains a query repository, but also complements ChatGPT and Claude with interface capabilities: you can use different APIs, enter messages by voice, and connect different roles in the same window.
Counting. One of the key limitations of modern language models is the size of the context window that the model can hold when generating text. This size is measured in special units - tokens. Tokens correspond to the basic word elements used within the model architecture. Special services such as Prompt Token Counter exist to count the number of tokens in queries to different models. In large language model-based solutions, token counting functions are usually built in from the beginning. In software terms, specialized Python libraries can be used for token counting, such as tiktoken for OpenAI models.
Frameworks for creating LLM agents
The Autonomous AI Agent Framework is a software platform that provides tools and capabilities for developing AI-based agents. It is similar to how ChatGPT users apply different chat rooms to store different contexts, but in a more controlled and metrics-driven way.
An example of such an Open Source solution is SuperAGI. The tool allows you to create, store and run your own autonomous agents based on Open AI, has a graphical user interface, gives agent performance metrics to optimize agent performance, monitors token usage to save costs, and supports local storage of agent dialogs.
There are also commercial solutions, such as Fine-Tuner. On this platform, users can create context-aware agents that can interact with the user's environment, such as searching for information on the Internet or sending emails. Another commercial product, Spell, allows delegating daily work routines to such agents and integrating agents with third-party services and data through a large library of plug-ins.
Working with LLM via API
Working with large language models, such as ChatGPT, is often done through APIs. This allows not only people, but also programs to interact with the models by sending requests through APIs.
To get an overview of working with APIs from different language models, it's worth starting with the Generative AI PlaybookI resource.It describes the practical aspects of using APIs from OpenAI, Stability.ai, Hugging Face, and others. and describes the general trend in this branch of machine learning.
Special access keys are used for authorization. As a rule, access to the API is paid. OpenAI provides a test credit of $5 to familiarize with the system capabilities. For testing OpenAI API settings it is convenient to use Promptclub service. The tool allows you to substitute and alternately test the prompt for a group of several parameters on various OpenAI models.
It is worth noting that APIs can often be handled using ready-made libraries. Usually Python is used as the main language for ML. OpenAI provides a Python library for accessing its models (not only GPT), which can be installed via the standard Python package manager
pip install openai
However, such libraries only create an interface to work with the API. The implementation of basic mechanics that are usually required in a program can be facilitated by using frameworks and libraries for working with LLM, which we will discuss below.
It is important to note that in addition to large models that require a lot of computing power, there are smaller models that can be run locally on a computer. Some of them are provided on company websites, while others are published on the HuggingFace portal.
Transformer Model Lair: HuggingFace
HuggingFace is a popular platform for working with machine learning models, in particular transformer models for natural language processing and computer vision.
HuggingFace provides the following features for working with large language models (LLMs):
- extensive library of pre-trained LLM models: BERT, GPT-2/3, BLOOM, OPT, T0 and many others with access via ML frameworks PyTorch or TensorFlow;
- support for popular datasets and uploading your own data;
- tools for LLM model training - special Trainer classes allow you to train the model on your own data, as well as built-in tools for logging and visualization of metrics;
- ready-made word and morpheme tokenization models for different languages;
- distributed learning tools on multiple GPUs/TPUs;
- A simple API for using pre-trained LLMs in applications.
HuggingFace makes it easy to use advanced AI models in products and research projects, including Open Source LLMs that you can run locally. What's particularly convenient is that you can access the models through the same Python library software tool, in particular the transformers library.
Compact Open Source LLMs
Shortly after the release of ChatGPT, the AI-enthusiast community began offering their own GPT models, which can be run locally and experiment with the AI model on your computer for free, or installed on a server and used as part of your own application infrastructure. The latter is especially important for those companies that want to use AI tools but are hampered by data privacy issues.
Such solutions still lag behind the more popular solutions that provide paid APIs, but they are rapidly approaching them. The most representative are the HumanEval and MBPP benchmarks, which determine the share of solved program tasks in the Python programming language.
Table with characteristics of compact OpenSource LLM models compared to commercial closed models (in bold).
There are also special adaptations of local LLM models for high-level code generation, for example, the smol developer project. The user describes the desired application or functionality in natural language in the form of a detailed prompt, and the tool generates the corresponding source code based on this description. The tool can be used both in API mode and for dynamic generation from project code.
LLM Frameworks
Frameworks for building language model-based applications allow you to integrate private or highly specialized data into the workings of commercial and Open Source models. Here are the main capabilities that such frameworks provide:
- access to models via convenient APIs
- tools to generate appropriate requests (prompts) for each model
- Ability to combine model responses with other application data sources
- integration of models into web, mobile and desktop applications
- Monitoring model usage and tracking errors
- result caching for performance optimization
- Load balancing when using models in scalable applications
- development and debugging tools to simplify work with models
That is, such frameworks take over the chore of model integration and allow developers to focus on the business logic of their applications.
LangChain is a popular Python-based LLM framework that can handle dynamic one-shot and few-shot prompt templates, asynchronously process queries to LLMs and cache results to save money, chain calls to LLMs, and combine results.
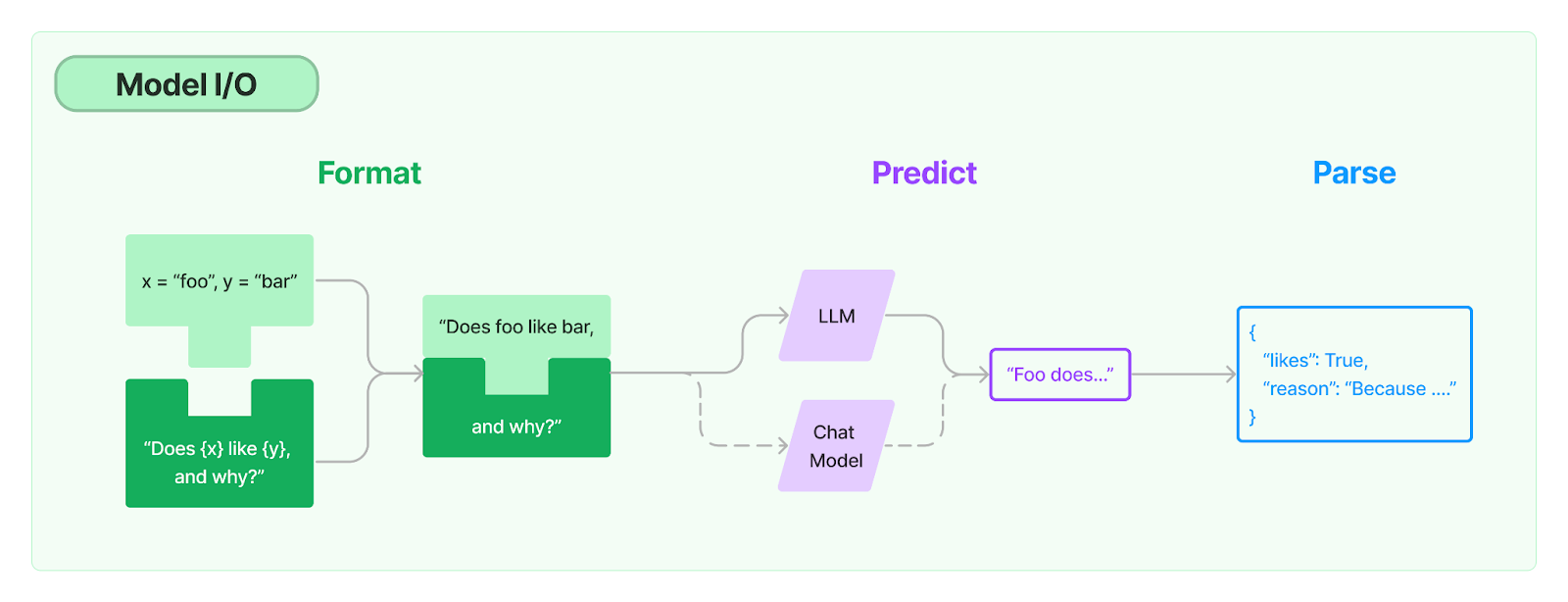
The main idea behind another framework, LlamaIndex, is to provide developers with convenient tools for extracting the right data from various sources, structuring this data and organizing quick access to it from the LLM. This helps to expand the context and knowledge available to the model when generating responses to user queries.
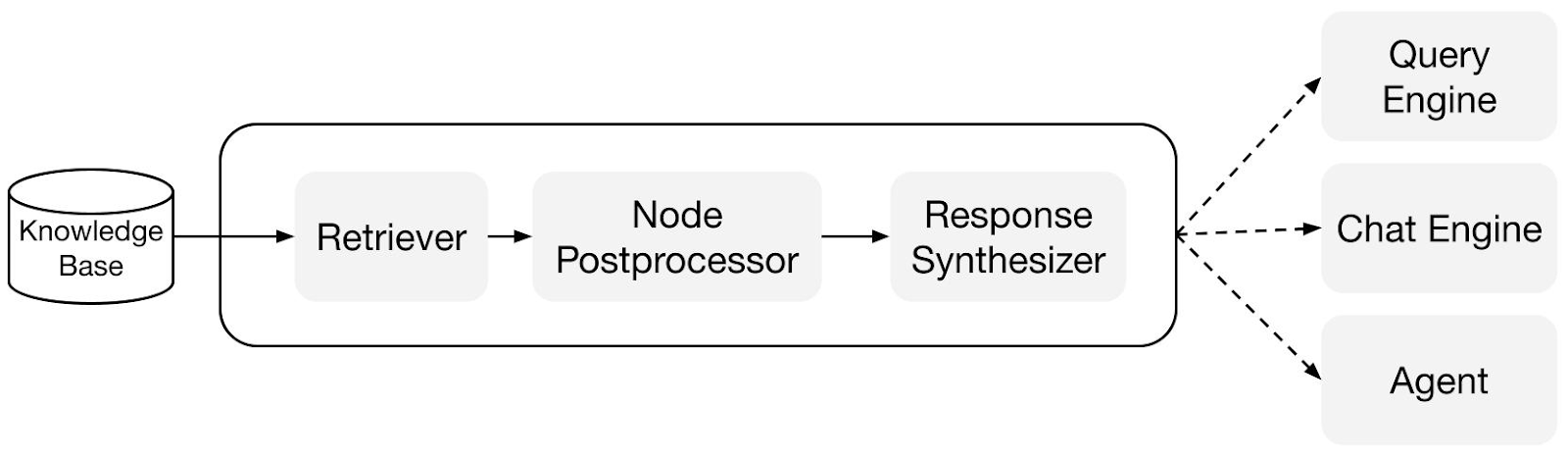
As a result, the LlamaIndex framework allows:
- upload documents from different sources such as local files, databases, APIs;
- convert these documents into structured Node-objects with all necessary meta-information;
- build indexes on top of Node-objects optimized for fast search;
- query these indexes and retrieve relevant context for the LLM;
- customize LLM response logic by combining different indexing, searching, and response synthesis modules.
LlamaIndex is able to connect to ChatGPT, LangChain, Docker containers and other data sources. You can also use special software solutions to work with your own data: Haystack or Sidekick.
LLM monitoring
One of the key problems of LLM is the inconsistency of the model's responses with the user's request or objective information. It is particularly difficult to track "hallucinations" - situations where the model follows the user's lead and generates new information that does not match the actual data. Sometimes it is enough to simply tell the network, "Now check your answer carefully to make sure there are no mistakes in names or fake recommendations," but often such self-criticism is not enough.
To address such issues, BerriAI has developed a Python package called bettershot to add language model-based error monitoring to applications and make it as simple and effective as using Sentry in traditional development.
Bettershot analyzes each query-response pair and determines whether the model's response matches the actual data. To do this, bettershot uses another language model (ChatGPT) that evaluates the relevance of the answer and the presence of "hallucinations". To make the evaluation as robust as possible, each query-response pair is analyzed 5 times and the most frequent solution is selected. This approach minimizes inconsistencies in the performance of the estimation model.
Conclusion
Large language models are a rapidly growing area of machine learning that is fundamentally changing the possibilities of building intelligent applications. For the tools described in this article, new releases are being made regularly. If you are interested in the topic of LLM, we advise you to explore the Awesome-LLM GitHub repository, as well as the LLMOps resource, which publishes up-to-date information on LLM development.