PDF data to HTML data extraction for “Dummies”
Selection of document scraping services. Overview of data that can be obtained from documents. Why PDF is so popular for data storage.
Journalists receive a lot of data in PDF format – it can be tables with data embedded in reports or spreadsheets that have been carefully saved as PDF files before being sent to you by email. But unless you convert the data into a spreadsheet, you will not be able to use it.
Fortunately, there are some excellent tools that can quickly and easily reformat your data. I’ve listed some of those that I’ve tried, and also gave some tips on how to deal with PDF data extraction in some more complex types of PDF files, including rotated tables, conversion of scanned PDF files and password-protected PDF files. Hope you will find the best way to extract data from PDF with one of these tools.
Tabula
This is one of my first choices because it is free and so simple to use. On their website, it is said that it was created by “journalists for journalists” and that’s probably the reason it is so popular with “non-technicians” like me.
I often need to extract data from PDF files. Tabula allows you to download the entire document and select only the tables you need. You can convert one table at a time or several, depending on the layout of your document, into CSV, TSV JSON files, which can be imported into Google Sheets (free), Libre Office Calc (free), Excel (not free) or any other program you prefer.
The only time I don’t use Tabula is when I deal with scanned PDF files or when the tables I want to convert are rotated 90 degrees.
Cometdocs
This tool is not least popular with journalists because Investigative Reporters and Editors members (IRE) receive free premium access, and it is designed for users. You can process up to five documents a week for free, but you will have to subscribe if you want to do more. The subscription will cost you $9.99 a month, but if you like it, you can get a lifetime membership for about $130.
Here’s how it works: upload or import the PDF document you want to convert, click convert, and choose between Excel and.ODS (which you can open in Libre Office). Unfortunately, there is no.CSV option. If you do not have one of these spreadsheet packages, you can upload the file to Google Disk and open it in Google Spreadsheets.
Cometdocs works quickly and efficiently, but its special advantage is that it performs Optical Character Recognition (OCR), so it can convert scanned PDF files. But it is better to check the converted document against the original to make sure that everything is converted correctly. This tool, like Tabula, cannot handle rotated tables.
Adobe Export PDF
This tool is not free, but accessible – about $24 per year. If you use Adobe Reader, which is Adobe’s free PDF reader, Export PDF allows you to convert a PDF document you opened in Acrobat Reader to Excel, Word, PowerPoint, or RTF. It works well and quickly with rather large documents. But like Tabula, it does not process scanned documents or rotated tables. Adobe Export PDF allows you automatically extract data from PDF to Excel – this is the main reason to use it.
Nitro Pro
If you have a Windows computer, Nitro is a great tool to process and convert PDF files to useful formats, but it’s not free (about $160), and the fact that it only works with Windows means it’s not available on any other devices.
Acrobat Pro
This one is available for Mac users but is also not free (about $15 per month and annual commitments).
Zanran
This British company has developed software to automate PDF processing. It is not free, but you can see its features by trying its demo version – if your document weighs 1.5 MB or less. You upload your PDF file, specify what you want to convert it to, give them your email address and they send you the converted document.
Zamzar
Another online conversion tool where you can upload your document, choose the format you want to convert it to and receive the converted document to the selected email address.
Extract tables from PDF, including rotated tables
Sometimes tables in PDF documents are rotated by 90 degrees. Before the conversion tool can identify them as text, you need to return the tables back to their normal orientation. Normal page rotation in Acrobat Reader or Preview will not work. You need to rotate the table itself. To do this, you need the right PDF editor, such as Acrobat Pro or Nitro Pro.
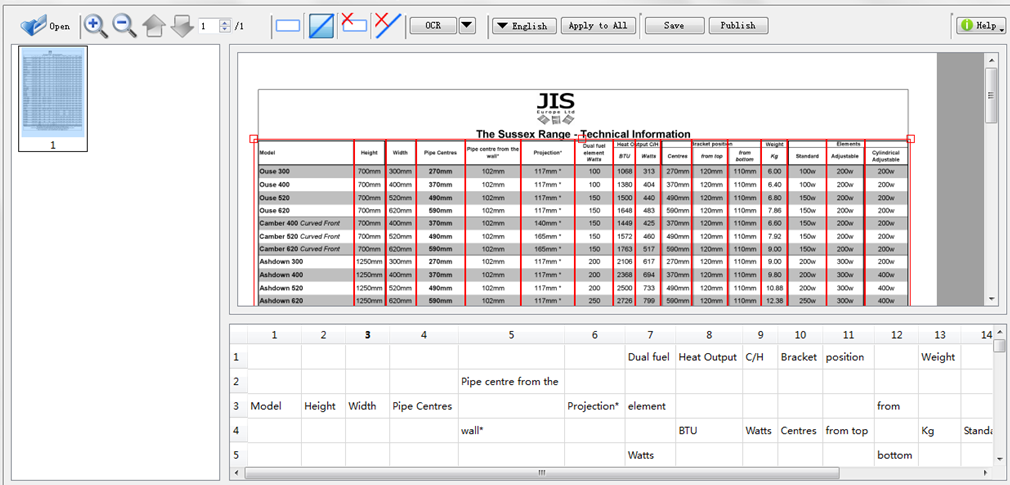
If you have Acrobat Pro, this is what you need to do to extract tables from PDF:
- If your tables are part of a larger document, open your document and use the “Organize pages” option to extract the pages with the tables you want to rotate. If you want to extract several consecutive pages, it is easier to extract them as separate files.
- Open a page with a table. Go to the View menu and rotate the table until it is in the right position.
- If there are headers and footers or any other text that does not rotate in the same direction as your table, you will not be able to cover them, only delete using the “Edit PDF” function.
- Go to the Enhance Scans option and select Recognize Text; check the settings to make sure the Save as editable text and images option is selected. This may take a few minutes, and then your table will rotate again by 90 percent.
- Go back to “View” and rotate the page until it appears to be in the right position again. Then save the file.
- You can try to convert your page to an Excel spreadsheet using the Export PDF function, but consider Tabula does it better.
- Always check the converted data against the original documents, because sometimes the eight can be mistaken for six or the letter “B”. But even if the converted document isn’t perfect, it is much faster than typing everything manually into a spreadsheet.
Convert scanned PDF files
In a scanned PDF file, the table will be identified as an image, not as text, so if you want to make PDF data extraction from the table, you first need to convert it to text using something with Optical Character Recognition (OCR). You can use Cometdocs, Acrobat Pro, or Nitro Pro. Acrobat Pro Enhance Scans should recognize text in your PDF file if the scan quality is not impaired. Sometimes it is worth trying to make a screenshot of the table you want to extract a separate PDF file before using the Enhance Scans tool. After the scanned document is converted to text and images, still save it as PDF and convert it to CSV with Tabula. And of course, always check your data against the original.
Password-protected PDF files
Sometimes PDF files are password-protected, so you can’t edit them or convert them to any other format. If you have a Mac with PDF preview, try to open the PDF in the preview mode and then select “Export as PDF” from the File menu. Open a new version of your PDF file and try to convert it to a spreadsheet and extract spreadsheet from PDF.