How to use Twitter API
How does the Twitter API operate. What data format does the twitter API operate with.
How to use Twitter API
A continuous flow of news, posts, publications, event reviews, goods, and services on social networks is a source of data that can be effectively used in business analytics and decision-making. We will discuss in this article how to use Twitter API and how to use Twitter search API.
Twitter has APIs that allow users to search for open tweets and extract the content by keywords or by individual user accounts. There are three types of APIs: Standard (free), Premium and Business. They differ in restrictions on data access, search operators, and Twitter technical assistance. Most often, it is enough to create a developer account and use the Standard API.

How does the Twitter API operate?
Suppose you want to collect all the newest tweets mentioning delicious food. A request may look like this:
- tasty food – will return tweets that contain both words – tasty and food, not necessarily in that order;
- “tasty food” will return the tweets with that phrase;
- “tasty OR food” will return the tweets that contain any of those words;
- #tastyfood will return tweets that contain hashtag #tastyfood
There are as well other operators that are well described in the documentation for Twitter developers and which allow them to narrow the search field. Some of them are only accessible for Premium and Business (Premium Operators) accounts. The Twitter API allows users to extract the newest tweets, best-known ones, or both.

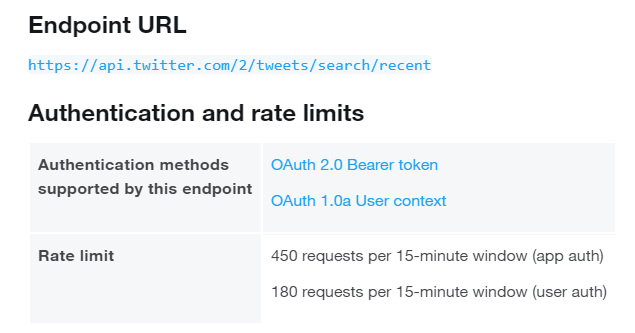
After you formulate a request, the API will send it to Twitter to extract tweets that match your search term. Depending on the type of your developer account, the API has some limitations on the number of requests per time unit. The Standard API allows you to send 180 queries every 15 minutes and use the 7-day-old Twitter archive. Each request returns 100 tweets, so this type of account allows you to extract 18,000 tweets every 15 minutes during the 7-day period. If you need to open the tweets that have been published in the last 30 days or even the full Twitter archive that has been in existence since 2006, or if you want to extend the outreach of a single request, you will need a paid Premium or Business API account.
The data is then sent back in JSON format, and, besides the tweet, contains metadata about each publication and its author. Therefore, you will need a JSON parser to transfer this information to a table format and/or import it into a database.
The time required for data collection depends on the number of appropriate tweets, the limitations of the request, and the time interval according to your account.
Let’s use the above-mentioned example. With the Standard API-account, our request #tasty will find 500 tweets published in the last 7 days. In order to extract them, we will need 5 requests and a few seconds. But the 7-day archive contains 90000 tweets that are relevant to our request. It will take 900 requests and five 15-minute intervals (just over an hour) to extract them.
Though the Standard API account only allows us to extract tweets that have been published in the last 7 days, users have the ability to extract data for a longer period progressing rather than oppositely. For instance, users can set up a sample of tweets that are published within the first hour of each week to be automatically generated. It must be understood that if this is an actual topic, some tweets that will be posted between the sample creation intervals can be omitted. If the topic is not relevant, you may find the repeats in the final table and then you will have to remove them.
A major difficulty in data compiling from Twitter is the need for basic programming skills and knowledge how to use Twitter API and the obtained output data. In this regard, Megaputer has created a tool for Twitter data extraction. This tool is part of the PolyAnalyst™ system. Its user-friendly graphical user interface (GUI) allows you to access Twitter without the programming necessity. Users only need to specify their account data, enter a query, and configure additional search options offered by the Twitter API platform (e.g. tweet language). PolyAnalyst™ extracts the data, automatically parses the resulting file in JSON format and then imports data to the table suitable for further analysis. In addition, the built-in Scheduler allows users to set up automated data extraction for the required period and update the analyzed data in the project.
How to collect data from Twitter using Python?
It worth a separate article to answer a question “How to collect data from Twitter using Python”. Tweepy is a main Python package that will manage how to download Twitter data using Python.