How to get YouTube comments: YouTube comment scrapers for programmers and everyone else
Tools to download YouTube comments and corresponding Python script. YouTube comment scrapers for programmers and everyone else.
There are two ways to download YouTube comments:
- Find the special ready- to- use software
- Or write the a parser script by of your own.
Tools to download YouTube comments
Some of the third party tools for web scraping YouTube can save your time and help you with data extraction even if you are not a programmer. The While some of themothers require from you some minimum programming language knowledge to be installed and use themed.
- YouTube Comment Extractor – an online YouTube comment scraper that pulls comments (and replies) from the a certain video and saves them to an Excel spreadsheet. All you need to do is to give it a link and a couple of settings using the web interface and push down the “Start” button.
- YouTube Comments Scraper – an interesting web data scraping application based on the technologies stack of Node.js, Express.js, React.js, Puppeteer and Socket.IO. It deals with Chromium headless browser (Puppeteer library) and works without a single request to the official YouTube scraper API. But it seems that the app is hosted on athe free Heroku server, so it can work a little bit slow.
- YouTube-Comment-Scraper-CLI – a Node.js application with a command line interface. Gets a video ID as a required argument, saves results in CSV or JSON formats or gives you an stdout stream data. Can treat replies in the same way as a regular comments.
Easy way to scrape YouTube comments – Python script
We will take a look at a short example that shows how to get YouTube comments and replies using YouTube API. It is supposed that you are already familiar with Python and have a Python interpreter installed on your computer.
Registration
First thing we need to do – is to get the API Key. Follow these simple steps:
- Register as a Developer here: https://developers.google.com/
- Create a new project in the Developers Console: https://console.developers.google.com/cloud-resource-manager

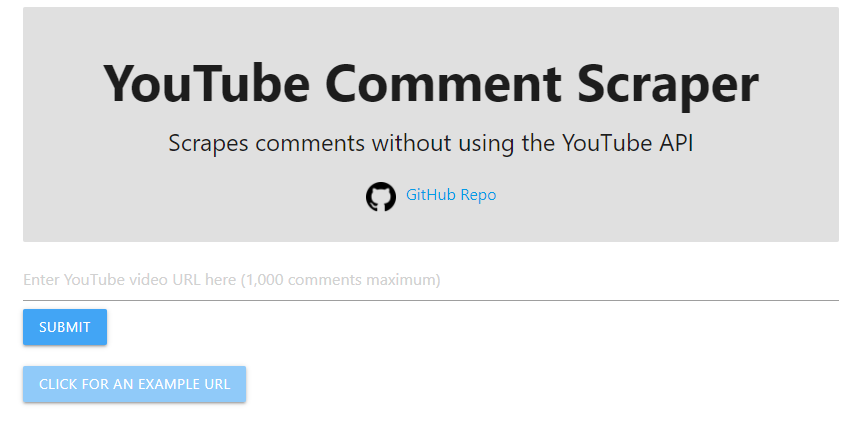
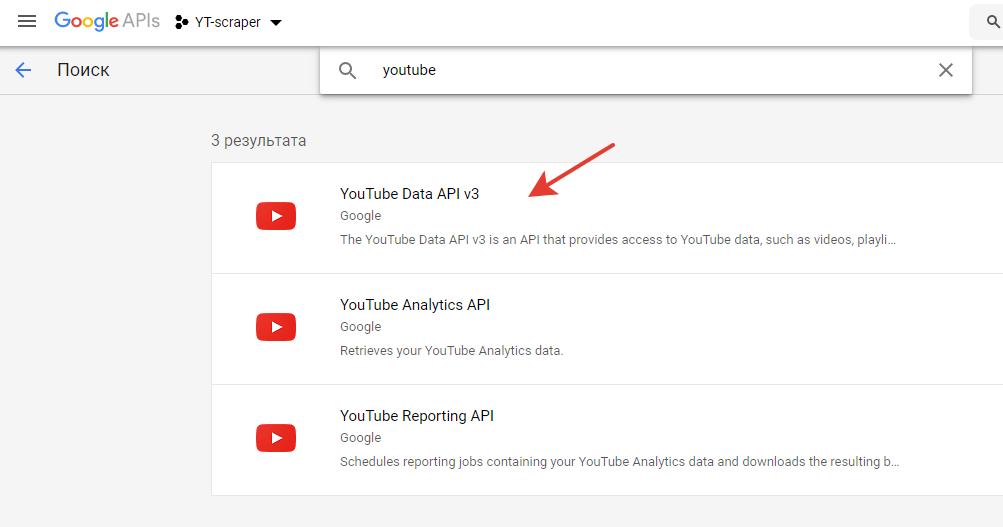
- Find and install YouTube Data API v3 in the APIs Library for your project: https://console.developers.google.com/apis/library
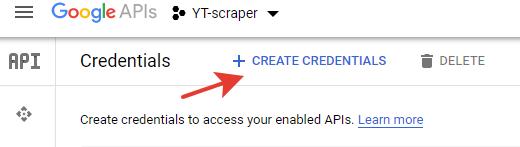
- In the Credentials section of your project create a new API Key
- Read the API documentation related to our topic: https://developers.google.com/youtube/v3/docs/commentThreads/list
Testing the API request
As you copied and saved your API Key, it’s time to dive into the code for some data crawling. Our task is to write a YT comment scraper that gets every comment’s text and author name under the video, knowing the video ID. (How to get a list of video IDs from any YouTube channel we described here.)
First of all, install the YouTube API wrapper for Python.
pip install google-api-python-client
Import the package into your project and write down the API Key.
import apiclient
KEY = 'YOUR KEY HERE'
Initialize the API Service that will send requests and try to scrape YouTube comments under any video (we took the video with ID 'oDf6t9Vec-U' as an example).
youtube = apiclient.discovery.build('Youtube', 'v3', developerKey=KEY)
video_id = 'oDf6t9Vec-U'
results = youtube.commentThreads().list(
part="snippet,replies",
videoId=video_id,
textFormat="plainText",
maxResults=100
).execute()
What’s going on here inside this code? With the command youtube.commentThreads().list(*args).execute() we are getting the a list of comments. The arguments we use here describe what exactly we want to get. We pass the maxResults value to receive as much data in one response as it’s possible in the specific textFormat for the specific videoId. We also pass the comma separated list to the part argument to see not only the top level comments (snippet), but the second level comments (replies).
Working with the data structure
for item in results['items']:
print(item)
Now, if we iterate through results items we will get the top level comment data inside item['snippet']['topLevelComment']['snippet'] – here you can see textDisplay and authorDisplayName.

It is not obvious, that we have got fewer items now than the total number of comments under this video on YouTube, because the second level comments can be found inside item['replies']['comments'] list and we have to check if the comment got any replies like this:
if 'replies' in item.keys():
for reply in item['replies']['comments']:
print(reply)
Inside we got reply['snippet'] that has the same fields as item['snippet']['topLevelComment']['snippet'].

Let’s write a function that gets the author name and comments text from snippet.
def build_comment(sn):
return {'author': sn['authorDisplayName'], 'text': sn['textDisplay']}
Recursive search
Now we can receive both comments and replies but we are still reaching the limit of 100 items during data parsing that we set as maxResults argument (default value is 20; 100 is the maximum value we can use).
Let’s write a recursive function.
def scrape(comments, video_id, token=None):
youtube = apiclient.discovery.build('Youtube', 'v3', developerKey=KEY)
if token:
# request with the pageToken
results = list()
else:
# request without pageToken
results = list()
for item in results['items']:
# working with the first level comments
pass
if 'replies' in item.keys():
for reply in item['replies']['comments']:
# working with the first level comments
pass
if 'nextPageToken' in results:
comments.extend(scrape(comments, video_id, results['nextPageToken']))
return comments
Look at the bottom “if” of the function. Inside the results of our query youtube.commentThreads().list(*args).execute() we may get the nextPageToken – it means that one more query can be sent to get the results from the next page of comments. We call our function inside itself passing nextPageToken and extending the comments list with the output data of this inner function.
NLet’s ow look now at the top “if” statement. There are two options:
- We call the function first time – there is no page token;
- We call the function all the next times – there is a page token.
For the first option, the query will look as we described above (see “Testing the API request”). For the second option, we should write the a command with the token:
results = youtube.commentThreads().list(
part="snippet,replies",
videoId=video_id,
pageToken=token,
textFormat="plainText",
maxResults=100
).execute()
And finally the “for” loop in our function will deal with the data structure, collecting comments and replies with the help of build_comment function like we described earlier.
The full code
To scrape YouTube comments python the script is below:
import apiclient # pip install google-api-python-client
KEY = 'YOUR KEY HERE'
def build_comment(sn):
return {'author': sn['authorDisplayName'], 'text': sn['textDisplay']}
def scrape(comments, video_id, token=None):
youtube = apiclient.discovery.build('Youtube', 'v3', developerKey=KEY)
if token:
results = youtube.commentThreads().list(
part="snippet,replies",
videoId=video_id,
pageToken=token,
textFormat="plainText",
maxResults=100
).execute()
else:
results = youtube.commentThreads().list(
part="snippet,replies",
videoId=video_id,
textFormat="plainText",
maxResults=100
).execute()
for item in results['items']:
comment = build_comment(item['snippet']['topLevelComment']['snippet'])
comments.append(comment)
if 'replies' in item.keys():
for reply in item['replies']['comments']:
comment = build_comment(reply['snippet'])
comments.append(comment)
if 'nextPageToken' in results:
comments.extend(scrape(comments, video_id, results['nextPageToken']))
return comments
if __name__ == '__main__':
comments_list = scrape([], 'oDf6t9Vec-U')
for x in comments_list:
print(x)
Conclusion
The most flexible result yYou can get the most flexible results by writing your own script and getting only the fields you need out of the data structure. But However, to save your time it is better to use the a third party YouTube comment scraper.