YouTube scraper creation: benefits and challenges
How to extract the necessary data from YouTube. What kind of difficulties will you face? Example of data extraction from Youtube service.
Here we will go through the main technologies of creating YouTube scraper and get closer to some Python script example for YouTube channel data crawling.
What information can be parsed on YouTube
Any data we see on YouTube in our common browser can be parsed:
- Channels,
- Playlists,
- Videos (including description and some statistics),
- Comments (YouTube comment scraper),
- Tags and categories.
The main goals of the YouTube scraper should be strictly defined. For example, we can parse:
- Trending videos to find out what themes are popular today;
- Videos views, likes and dislikes statistics by a special category or a query;
- Videos information from a channel or playlist;
- Comments beneath the special video or even comments from the whole playlist or channel to get the feedback from our target audience;
- Etc.
Widely used YouTube web scraping technologies
Based on our goals and benefits and the technical requirements we chose the methods to scrape YouTube data. Writing Python scripts for YouTube data extraction is a widespread and flexible solution.
For Python developers Google offers the API wrapper – google-api-python-client – that allows interacting with many Google services including YouTube (use google-api-python-client version 1.8.0 to avoid dependencies problems).
If our task does not require a high volume data parsing – we can write, e.g., YouTube comment scraper with selenium, the Python tool that automates browser.
Frequent difficulties in scraping elements on YouTube
In short terms, the difficulties of web scraping YouTube are the following:
- Besides the usual get-methods restrictions, YouTube API has quotas that may come to an end fast if our scraper consumes a lot of data;
- Selenium is good to work with a single video page on YouTube, but it seems too slow for data parsing from thousands of videos;
- Authorization and tokens on YouTube can be the big obstruction no matter what tools you use for parsing especially for the first time.
Elegant Python example to scrape YouTube channel videos
One of the possible solutions is to use YouTube AJAX service directly to get a response with JSON-data. Let’s imagine that we are going to scrape youtube video and need to get the list of videos from any channel knowing its URL.

Our first step is to receive the valid token. Writing down all the necessary headers parameters, we send the GET request to our channel URL (https://www.youtube.com/c/TED/videos). Token is stored within the script, so we have to split the contents of the page.
import requests
channel_url = 'some youtube channel full link here'
# making request to get 80 chars token
headers = {
'user-agent': 'some valid UA',
'x-youtube-client-name': '1',
'x-youtube-client-version': '2.20200429.03.00',
}
token_page = requests.get(channel_url, headers=headers)
token = token_page.text.split('"nextContinuationData":{"continuation":"')[1].split('","')[0]
Printing out the token_page.text we get some long JS string:
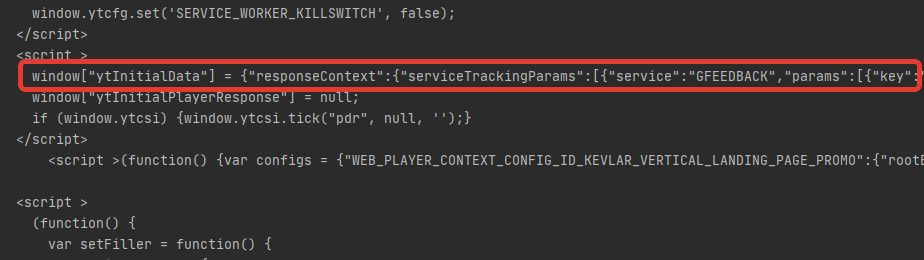
In the middle of this string we find the token:

Now we have the following dictionary with our token:
# build params dict for the future requests
params = {
'ctoken': token,
'continuation': token
}We will get data in a loop. The condition to stop will be an absence of token for the next request:
# parse data while we have token
stop = False
ids = list()
while not stop:
passWithin our loop we make the POST request and parse a JSON response (a little bit complex, do not confuse with the keys):
# post request to get JSON-data
ajax_url = 'https://www.youtube.com/browse_ajax'
r = requests.post(ajax_url, params=params, headers=headers)
r_json = r.json()[1]['response']
channel_data = r_json['continuationContents']['gridContinuation']Now the variable channel_data contains the part of JSON with the list of videos, but before we deal with it, we need to check if we get the last chunk of data – the indicator is the presence of token in this part of JSON:
# trying to get token for the next request
try:
token = channel_data['continuations'][0]['nextContinuationData']['continuation']
except:
# failed to get token -> no requests anymore
stop = TrueAnd finally we go through the channel_data items and grab videos IDs inside the result list:
# iterate through the channel_data
for item in channel_data['items']:
video_id = item['gridVideoRenderer']['videoId']
ids.append(video_id)The variable item contains the following JSON, relating to the video preview and main info:

At the top we see the video id – "videoId": "8atXMqZ_w0M" – that can be used as a part of full link: https://www.youtube.com/watch?v=8atXMqZ_w0M .
By this solution we overcome YouTube scraper API limits and still use JSON data that is fast and easy to work with.
Conclusions
As any other social network YouTube, on the one hand, protects itself from frequent requests mainly with the API limits, and on the other hand, gives developers a good documentation and ready to use libraries. Even with a little knowledge of Python we can find the ways for web data scraping on YouTube by API, from the browser instance with selenium or from AJAX service directly.