How to automatically pull data from a website
How to pull data from a website into Excel using simple Python script based on requests and BeautifulSoup libraries.
Excel spreadsheets are a popular data format familiar and comprehensible to many people. Most of web services and applications for data extraction allow users to save a result on a Google Drive as an online spreadsheet or on a local computer as a simple Excel workbook or CSV file.
Today we will discuss how to automatically pull data from a website and save it in XLSX format using the Python programming language. Working with Google API and online spreadsheets is beyond the scope of this article.
Python community provides several packages for working with Excel to developers:
- Xlwt – works with old versions of Excel (95 – 2003).
- XlsXcessive – provides a Python API for writing Excel/OOXML compatible .xlsx spreadsheets.
- Openpyexcel – a Python library to read/write Excel 2010 xlsx/xlsm/xltx/xltm files.
- XlsxWriter – a Python module for writing files in the Excel 2007+ XLSX file format.
- Pandas – a popular tool for working with structured (tabular, multidimensional, potentially heterogeneous) and time series data. Pandas is one of the best packages for data analysis. And, yes, it can save data into an Excel file for us.
Any of these packages are suitable for the task of automated data scraping from websites into Excel. And while all you need isjust to save a file quickly and see the result in Excel you will see no differences between them. The choice of the a certain tool depends on what exactly you want to do with your data after you pulled it from the web:
- What version of Excel do you need?
- Will you need special formatting for your data?
- Will you store it on one or several sheets?
- How many rows do you need to save at once?
- Will you update an existing file?
Read the documentation and make sure that all advanced features you need are available for the package you are going to choose.
How to pull data from a website into Excel
Now we will take a look at a simple ready- to- use example of how to automatically pull data from a website and save it in the XLSX format (Excel 2010 and newer).
Our quick tutorial should be helpful if you are familiar with common data structures in Python – lists and dictionaries – and want to convert them into the Excel format. Those who have some experience in pandas and creating DataFrames will also find here an example of saving DataFrames into Excel.
The task is extremely simple. Imagine that we want to scrape search results from Yahoo for some random query. To make it short and easy, pagination issues will be ignored, first page results are enough for us at this moment.
Requirements and imports
Here are the minimum requirements we need:
- beautifulsoup4==4.9.3
- requests==2.25.0
- numpy==1.19.4
- openpyxl==3.0.5
- pandas==1.1.5
Our imports are the following:
import requests
from bs4 import BeautifulSoup as bs
from pandas import ExcelWriter, DataFrame
Requests and bs4 will be used for web scrapping. DataFrame is pandas representation of data and it is easy to guess that ExcelWriter will help us write data into an Excel file.
Openpyexcel is an engine for ExcelWriter, it should be installed, but there is no need to import it.
Web data parsing with requests and BeautifulSoup
As a first step we make a get request with some test query to Yahoo (“excel tutorial”) and prepare a BeautifulSoup HTML parser that will work with a response text.
# get data from Yahoo search
data = list()
url = 'https://search.yahoo.com/search?p=excel+tutorial'
response = requests.get(url)
soup = bs(response.text, 'html.parser')
Go through the h3 elements with class “title ov-h” containing titles and full URLs of the search results. To get more fields, let’s separately take out site URLs with splitting.
# add results to our list
for item in soup.find_all('h3', class_='title ov-h'):
item_url = item.find('a').get('href')
line = {
'title': item.text,
'site': item_url.split('/')[2],
'full link': item_url,
}
data.append(line)
So we get the line dictionary with 3 fields and add it to the data list. Having printed out the data we will see that everything works fine:

Saving data from Python list of dictionaries into Excel
After the parsing algorithm is ready we define the Excel file path, field titles (from the keys of the first dictionary in the data list) and make a pandas DataFrame containing our data:
file = 'excel scrape data from website.xlsx'
data_headers = list(data[0].keys()) # column titles
df = DataFrame(data) # make pandas DataFrame from our data list of dictionaries
And finally, we write our data to Excel using a context manager to prevent errors:
# context manager saving DataFrame to Excel
with ExcelWriter(file, engine='openpyxl', mode='w') as writer:
df.to_excel(
writer,
index=False,
header=data_headers,
sheet_name='MyDataSheet',
freeze_panes=(1, 0)
)
Notice that here we tell pandas to use openpyexcel as an engine to create Excel file and call to_excel method with several options:
- index – make it False, otherwise the first column will be filled with indexes;
- header – requires a list of column titles, it really makes sense to define here some custom values different from what we use in our data;
- sheet_name – by default it will be “Sheet1”, but we can specify any other name;
- freeze_panes – defines the number of rows and columns to be freezed, tuple (1, 0) means that we want to freeze the first row with captions.
The output Excel file
It’s time to check the result. After scraping is done we see the file “excel scrape data from website.xlsx” next to our script file:
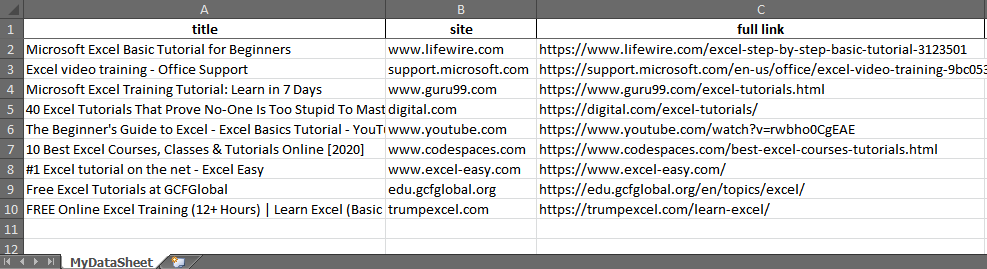
There are definitely many things to improve – set the correct columns width, replace NaN values, maybe exclude some fields from data or merge some cells, change the columns order and so on. But the basics you see in our script are enough to scrape data from a website to Excel.