Creating Amazon scraper: challenges and features
How to extract the necessary data from a product card on Amazon. What kind of difficulties will you face? Overview of the main challenges in scraping.
For many reasons Amazon data is valuable for internet retailers, business analytics and even common people, so data parsing from Amazon is highly demanded. Let’s discuss the challenges of web scraping Amazon and the ways to overcome the difficulties of data extraction.
Is it legal to obtain data by web scraping Amazon?
Any data you get by using Amazon scraper can be received by manual copying from the site in your browser. So it is legal to obtain data from the open source, no matter what tools you use on the client side: your browser and your mouse or some special script that sends HTTP requests like any browser and gets responses with the data.
Why is data scraping with Amazon difficult?
We want to create Amazon scraping tool to obtain data, Amazon tries to protect data, building ingenious algorithms of defense. These algorithms are evolving and changing – here is the main reason, why it’s hard to scrape Amazon.
There are 3 ways to get data from site:
- Parsing HTML of the specific page
- Interacting with the site API
- Controlling browser instance
It would be a good idea to combine all of them during Amazon web scraping.
Navigation and pagination
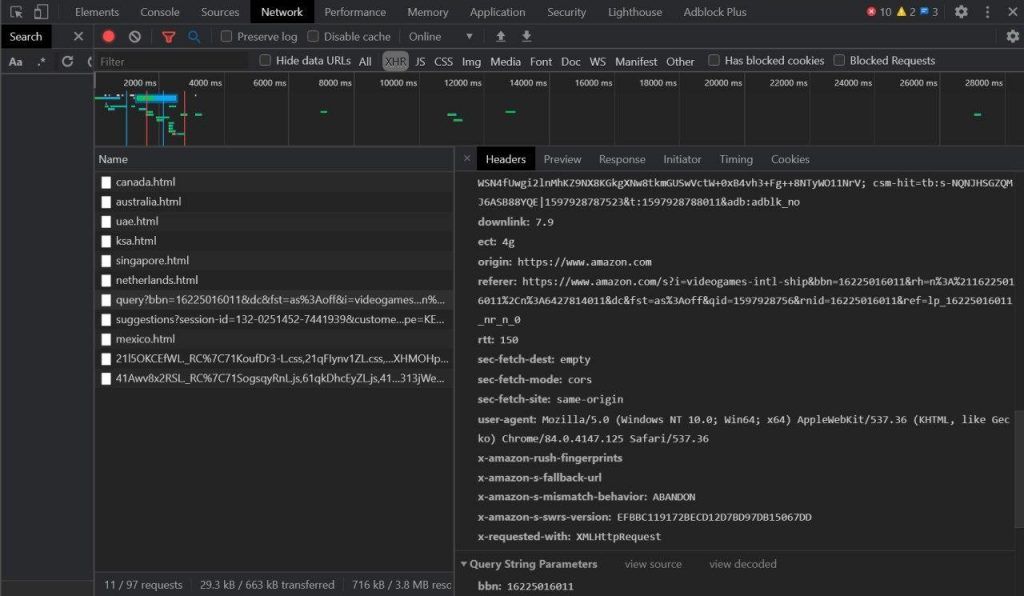
First of all, we have to select the category of goods or make a search query to get the page with the list of goods. It is easy with the browser instance but quite complex with the direct request – just take a look at the URL of any category to understand why.
The next issue is pagination – we have to find some way to get total pages within the category and to navigate through them. This is solvable with the browser instance, but working with the site API leads us to the limit of 100 goods per query with no chance to specify offset or page number. Moreover API response for some goods can be different from the data on site, and it would be the real headache for us.
Parsing speed
Data crawling speed is the next issue. We should know that controlling browser (even in headless mode) is extremely slow, so our goal is to work with scraper API or to parse the specific pages HTML. But anyway there are limits on the frequency of requests, so we have to make artificial pauses with random intervals between requests. To make our script faster we could use asynchronous requests with willingness to be blocked by Amazon a couple of times before we find the right balance of thread numbers, speed and chance to get our script banned.
Requests limits
Total number of requests from one IP address is limited too. We need to stock up a lot of proxies and find the easy way to change them automatically. Proxies that are different only in the last section or port numbers won’t fit us, because they will be blocked by Amazon in seconds. Pool of high quality proxies noticeably increases our costs but such is the recipe of success for web data scrapping on an industrial scale.
Human-like behavior
And last issue but not least. Making request to the server, your browser deals with the session details that is usually stored in cookies and is passed in request’s headers. While web scraping we use HTTP-client instead of browser and Amazon “knows” by empty headers that our specific request comes from script, not from live person.
The same thing with controlling browser instance (headless or not) – our default cookies would be wrong for Amazon. In both cases Amazon will give us 503 ERROR or something similar. To avoid it we have to supply our script with the right session details.
Using Network tab of DevTools in our browser we can see how the request headers and cookies should look like. Finding the way to get all necessary session IDs automatically is a complicated task, but it is solvable. Of course we need specify the human-like User Agent – the field with information about our browser and OS – in the request headers.
Amazon tries to identify bots and crawlers, so our main challenge is to bypass its defense algorithms and make it “think” that our scrapping tool is just a human with a normal browser.
5 reasons why scraping data from Amazon becomes more complex
Summing up the difficulties of Amazon web scrapping, we got the following:
- Navigation and querying – it’s not easy to build the URL for request of certain goods category or search query on Amazon.
- Selection of headers and cookies – every request should be provided with the correct session information, otherwise we will not get any data.
- Blocking by IP – Amazon uses a clever algorithm that determinates requests from the similar IPs.
- API requests limits and search methods limits – it’s impossible to get all goods of the selected category by API because of search methods limits and obstructed results pagination (or offset).
- API responses can be different from the data on site – for some goods the result we see in our browser is not equivalent to the result of querying by API.