10 modern tools to parse information from websites, including competitors’ prices
10 solutions to monitor competitor prices. Overview of tools and services.
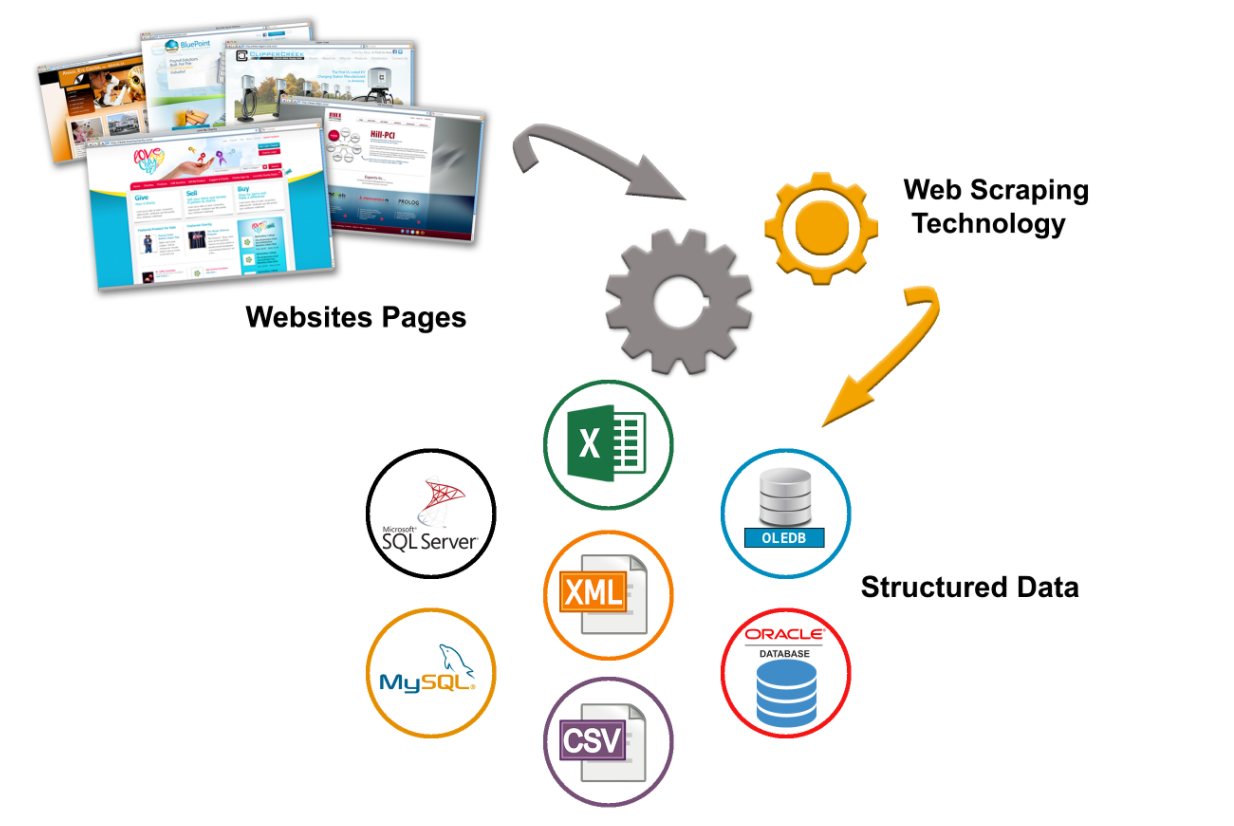
Web scraping tools are designed to retrieve, collect and share any open information from websites. These resources are needed, when any data from the Internet, needs to be quickly spun and stored in a structured form. Site scraping is a new data entry method, that does not require re-entry or copying. For example, this service (https://xmldatafeed.com) uses parsing to monitor competitor prices for retailers.
This kind of software searches for information under user control or automatically by selecting new or updated data and storing it in a way that the user has quick access to it. For example, using parsing, you can collect product and price information from the Amazon website. Below we’ll look at web-based data extraction tools and the top ten services that can help collect information without having to write special program codes. Parsing tools can be used for a variety of purposes and scenarios, and consider the most common uses that may come in handy.
Data Collection for Market Research
Web-based data mining services will help you keep track of where your company or industry is going in the next six months, providing a strong foundation for market research. Parsing software is able to retrieve data from multiple data analytics providers and market research firms, and then bring that information into one place of reference and analysis.
Retrieval of contact information
Parsing tools can be used to collect and organize data, such as mailing addresses, contact information from various websites and social networks. This allows you to create convenient contact lists and all related information for your business – information about customers, suppliers or manufacturers.
Solutions for downloading from StackOverflow
With site parsing tools, you can create offline use and storage solutions by collecting data from a large number of web resources (including StackOverflow). In this way, you can avoid dependency on active Internet connections, since the data will be available regardless of whether you can connect to the Internet or not.
Searching for jobs or employees
For an employer, who is actively looking for candidates to work in his company or for a job seeker who is looking for a particular position, parsing tools will also become indispensable; with their help, you can set up data sampling based on the various filters, that come with it and effectively obtain information without routine manual searches.
Price tracking in different stores
Such services will be useful also for those who actively use online shopping services, tracking prices for products, looking for things in several stores at once. This is exactly the approach used in parsing and price monitoring services.
What is web scraping in Python?
It definitely worth a separate article «What is web scraping in Python», but saying shortly: Python is a programming language well suitable for scraping.
The top 10 web-based data collection tools:
Let’s try to consider the 10 best parsing tools available. Some of them are free, some give you a free look for a limited time, some offer different pricing plan.
1. Import.io
Import.io offers a developer easily to create his own data packages: you only need to import information from a certain web page and export it to a CSV. You can extract thousands of web pages in minutes without writing a single line of code, and create thousands of APIs according to your requirements.
The service uses the latest technology to collect huge amounts of information needed by the user, at a low cost. Together with the web tool, free applications for Windows, Mac OS X and Linux are available to create data extractors and search robots, that will ensure data download and synchronization with your online account.
2. Webhose.io
Webhose.io provides direct access in real time to structured data from parsing thousands of online sources. This parser is capable to collect web data in more than 240 languages and save the results in various formats, including XML, JSON and RSS.
Webhose.io is a web browser application, that uses its own data parsing technology to process huge amounts of information from multiple sources with a single API. Webhose offers a free plan for handling 1000 requests per month and $50 for a premium plan that covers 5000 requests per month.
3. Dexi.io (formerly CloudScrape)
CloudScrape is capable of parsing information from any website and does not require downloading additional applications, just like Webhose. The editor installs his own search robots and retrieves data in real time. The user can save collected data in the cloud, such as Google Drive and Box.net, or export data in CSV or JSON formats.
CloudScrape also provides anonymous access to data, offering a number of proxy servers that help hide user identities. CloudScrape stores data on its servers for 2 weeks, then archives it. The service offers 20 working hours free of charge, after which it will cost $29 per month.
4. Scrapinghub
Scrapinghub is a cloud-based data parsing tool, that helps you select and collect the necessary data for any purpose. Scrapinghub uses Crawlera, a smart proxy rotor equipped with mechanisms that can bypass the protection against bots. The service is able to cope with huge amounts of information and robotic-protected sites.
Scrapinghub transforms web pages into organized content. The team of specialists ensures a personalized approach to customers and promises to develop a solution for any unique case. The basic free package gives access to one search robot (processing up to 1 GB of data, then – $ 9 per month), the premium package gives four parallel search bots.
5. ParseHub

ParseHub can parse one or more sites, that support JavaScript, AJAX, sessions, cookies and redirects. The application uses self-learning technology and is able to recognize the most complex documents on the network, then generates an output file in the format the user needs.
ParseHub exists separately from the web application, as a desktop program for Windows, Mac OS X and Linux. The program provides five free trial search projects. The Premium price plan for $89 includes 20 projects and processing of 10 thousand web pages per project.
6. VisualScraper
VisualScraper is another software for parsing large amounts of information from the network. VisualScraper extracts data from multiple web pages and synthesizes the results in real time. In addition, data can be exported in CSV, XML, JSON and SQL formats.
A simple interface like point and click helps you use and manage your web data. VisualScraper offers a package with processing of more than 100 thousand pages at a minimum cost of 49 dollars per month. There is a free application similar to Parsehub available for Windows with additional paid features.
7. Spinn3r
Spinn3r allows you to parse data from blogs, news feeds, RSS and Atom news channels, social networks. Spinn3r has an “updatable” API, which makes 95 percent of the indexing work. This includes enhanced anti-spam protection and enhanced data security.
Spinn3r indexes content like Google and stores extracted data in JSON files. The tool constantly scans the network and finds updates from multiple sources; the user always has real-time updates. The administration console allows managing the research process; full-text search is available.
8. 80legs
80legs is a powerful and flexible web site parsing tool that can be tailored very precisely to user needs. The service handles amazingly huge amounts of data and has an immediate extraction function. Customers of 80legs are giants like MailChimp and PayPal.
The “Datafiniti” option makes it possible to find data super-fast. With this option, 80legs provides a highly efficient search network that selects the data you need in seconds. The service offers a free package – 10 thousand links per session, which can be upgraded to INTRO package for 29 dollars a month – 100 thousand URLs per session.
9. Scraper
Scraper is an extension for Chrome with limited data parsing features, but it’s useful for online research and exporting data to Google Spreadsheets. This tool is intended for both beginners and experts who can easily copy data to the clipboard or spreadsheet repository using OAuth.
Scraper is a free tool, that runs directly in your browser and automatically generates XPaths to determine the URLs you want to check. The service is simple enough, it doesn’t have full automation or search bots like Import or Webhose, but it can be seen as an advantage for beginners, because it doesn’t take long to get the results you need.
10. OutWit Hub
OutWit Hub is a Firefox add-on with dozens of data extraction features. This tool can automatically view pages and store the extracted information in a format suitable for the user. OutWit Hub offers a simple interface for extracting small or large volumes of data as needed.
OutWit allows you to “pull” any web page directly from your browser and even create automatic agents in the settings panel to extract data and save it in the desired format. It’s one of the easiest free web-based data collection tools that doesn’t require special knowledge in coding.