Flow-Based Programming: the Mastermind behind NoCode
One of the basic concepts underlying NoCode platforms is Flow-Based Programming. In this article, we will review the history of development and current examples of FBP-inspired NoCode systems.
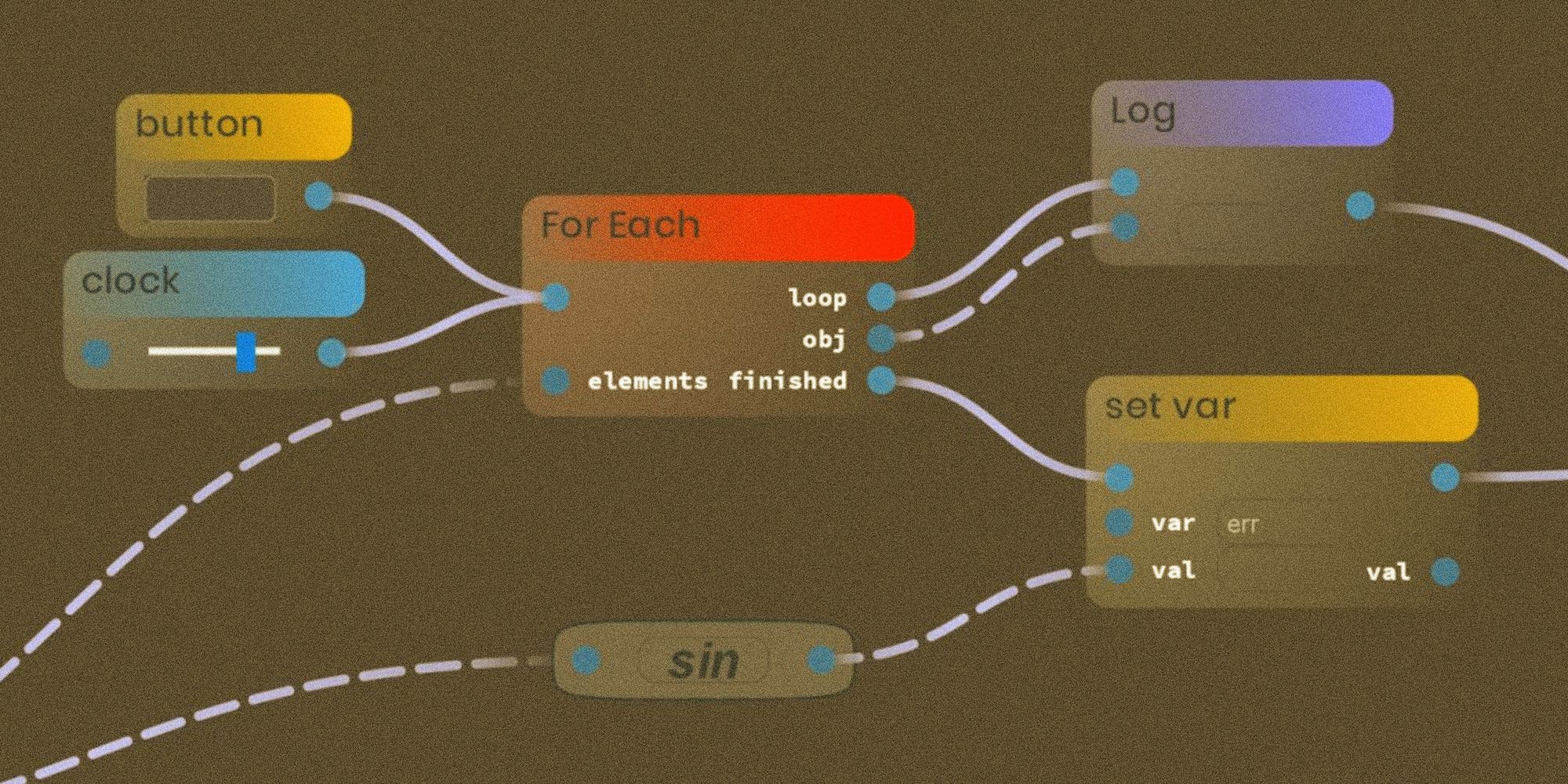
Most programs operate on a computational model, which can be designated as Control Flow. The corresponding architecture which provides control flow is called von Neumann architecture. A computing machine in the von Neumann architecture consists of two key nodes: processor and memory.
Processed information is stored in memory at specific addresses. A program in the Control Flow approach is a sequence of instructions that are loaded into the registers of the processor when the program is executed. After one instruction is executed, the processor moves on to the next.
Despite its prevalence, the Control Flow model has a few drawbacks:
- It is difficult to implement an efficient multiprocessor system. Working with multiple processors leads to problems of shared non-blocking memory access and data synchronization between processors.
- The data to be processed must first be loaded from memory into the registers of the processor, and then returned after the calculations have been performed. As a result, the processor sits idle for much of the time waiting for the data to be loaded.
- The simplicity of the model requires the use of the most universal structural units, which affects the performance of the system for highly specialized tasks.
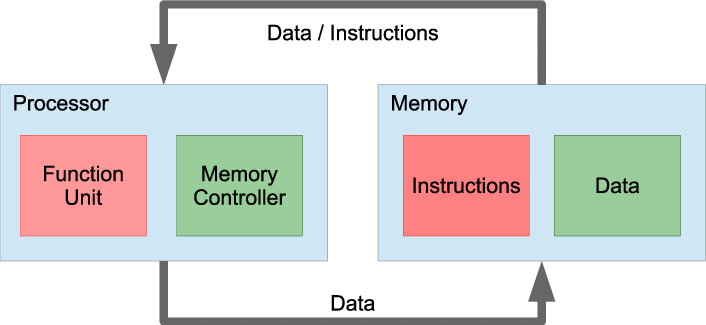
Data Flow. An alternative approach to building a computation model is the Data Flow model. The key differences of this model are as follows:
- A computational graph is used instead of a sequence of commands. The node of the graph represents the operator, the edges represent the interconnections of the nodes through which the data is distributed. An operator in a node comes into execution when all necessary data comes in.
- Addressing is not separated into in-memory and processor addressing. All data is transmitted and stored as "node label" and "transmitted value" pairs. Data availability for a node is determined by the availability of values for the same label. For this purpose, physical hardware associative memory or software structures – hash tables – can be used.
The main advantage of the Data Flow architecture is its scalability. The entire range of tags and nodes can be distributed among devices without taking additional measures for synchronization - such systems are already asynchronous by their structure.
In the hardware world, the best known example of an "iron" Data Flow architecture is PLDs – programmable logic integrated circuits. Such circuits consist of configurable logic blocks, which can be reprogrammed at the physical level for the required task. PLDs are used in tasks involving a very large number of I/O ports, neurochips, high-speed data transmission devices, as well as for cryptographic operations and simulation of quantum computing.
However, in terms of computers for the general audience, Hardware has taken the path of a simpler and more versatile architecture that supports the Control Flow concept. The Data Flow approach has evolved to a greater extent with respect to networking and microservice application architectures, however, standard von Neumann architecture solutions are used in every node of such hard- and soft-solutions.
Flow-Based Programming
In the 1970s J. Paul Morrison proposed the concept of Flow-Based Programming (FBP). This is a programming paradigm which defines applications as networks of nodes exchanging data over predefined message paths, where node connections are specified externally. Nodes are a kind of "black boxes" that developers can endlessly reuse and connect to form new applications without having to make internal changes. FBP networks are made up of components that communicate using messages called Information Packets.
Over time, the approach has come to be perceived more broadly than originally and has been used as a design template for the organization of better managed business processes. Components can be perceived as classes in object-oriented programming (OOP), and objects in the form of specific instances of components - as objects in the OOP paradigm.
A special language is used to develop such graph diagrams, the scripts are stored as .fbp text files or in a special graph notation for .json. Below is an example from the publication The state of Flow-based Programming and the corresponding diagram in DrawFBP:
INPORT=ReadFile.NAME:IN # Input port
OUTPORT=DisplayLines.OUT:OUT # Output port
ReadFile(io/ReadLine) -> Filter(app/StartsWith) ACC -> DisplayLines(cli/Printer) # Main flow
Filter REJ -> IN Reject(Drop) # Using custom port names
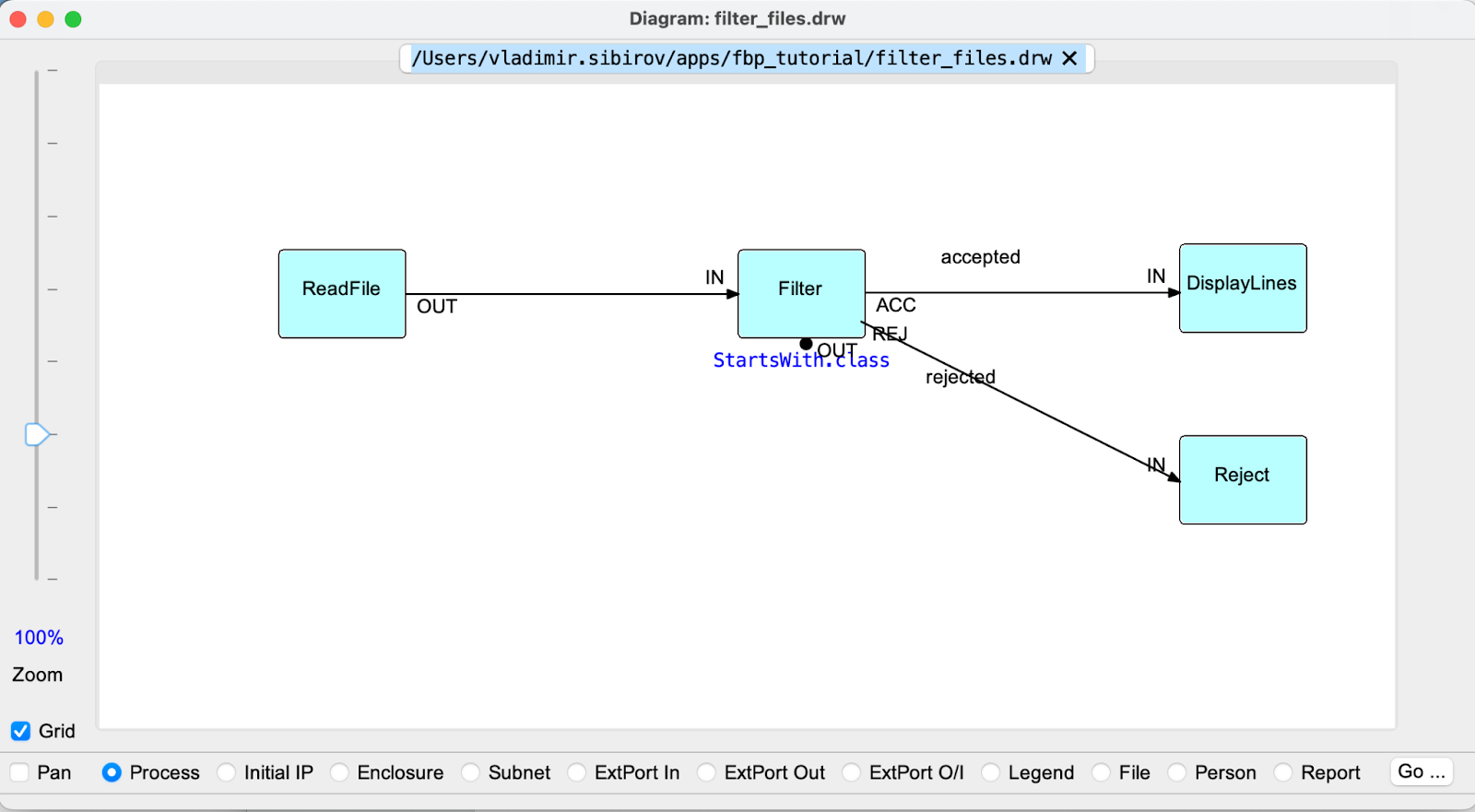
It is important to understand that each node in a graph can represent a graph, and this nesting of programs is a powerful component of FBP design to simplify the management of large programs.
One of the first implementations of web-based FBP ideas was NoFlo, a JavaScript and Node.js-based implementation of FBP. Although J Paul Morrison himself argued in a blog post that such examples are "FBP-inspired systems" rather than pure FBP. FBP-inspired systems refer to systems that use the FBP concept but do not fully follow it and may include other programming concepts. For example, systems based on data streams may use FBP to organize components and data transfers, but at the same time use parallel computing to organize data processing.
In the table below we have compared the key differences between the traditional approach and FPB.
Note that the classic development problems are inherent in FBP as well:
- transfer of low-level tasks to a high level of abstraction;
- generalization in the components of too broad a logic;
- increasing complexity in support as the system grows.
However, many of these problems in the FBP concept are solved at a lower cost than in classical development.
Examples of FBP and FBP-inspired Systems implementation in various fields
FBP ideas have been implemented in the form of special libraries for classical programming languages:
- Python: Ryven, PyFlow
- Go: GoFlow, Flowbase, Cascades
- Java: JavaFBP (+ DrawFBP editor)
- JavaScript: NoFlo (+ Flowhub platform), CodeFlow
- PHP: PhpFlo, Railway-FBP
- Rust: Fractalide
- Elixir: ALF, ElixirFBP
At the same time, the common FBP protocol allows to encapsulate different technologies together and obtain multistack solutions. That is, applications can simultaneously use different technologies and programming languages, which allows developers to choose the most appropriate tools for specific tasks. This makes the FBP approach flexible and adaptive to business requirements.
In addition, FBP ideas are used to create distributed applications running on multiple nodes. This approach improves application performance and stability.
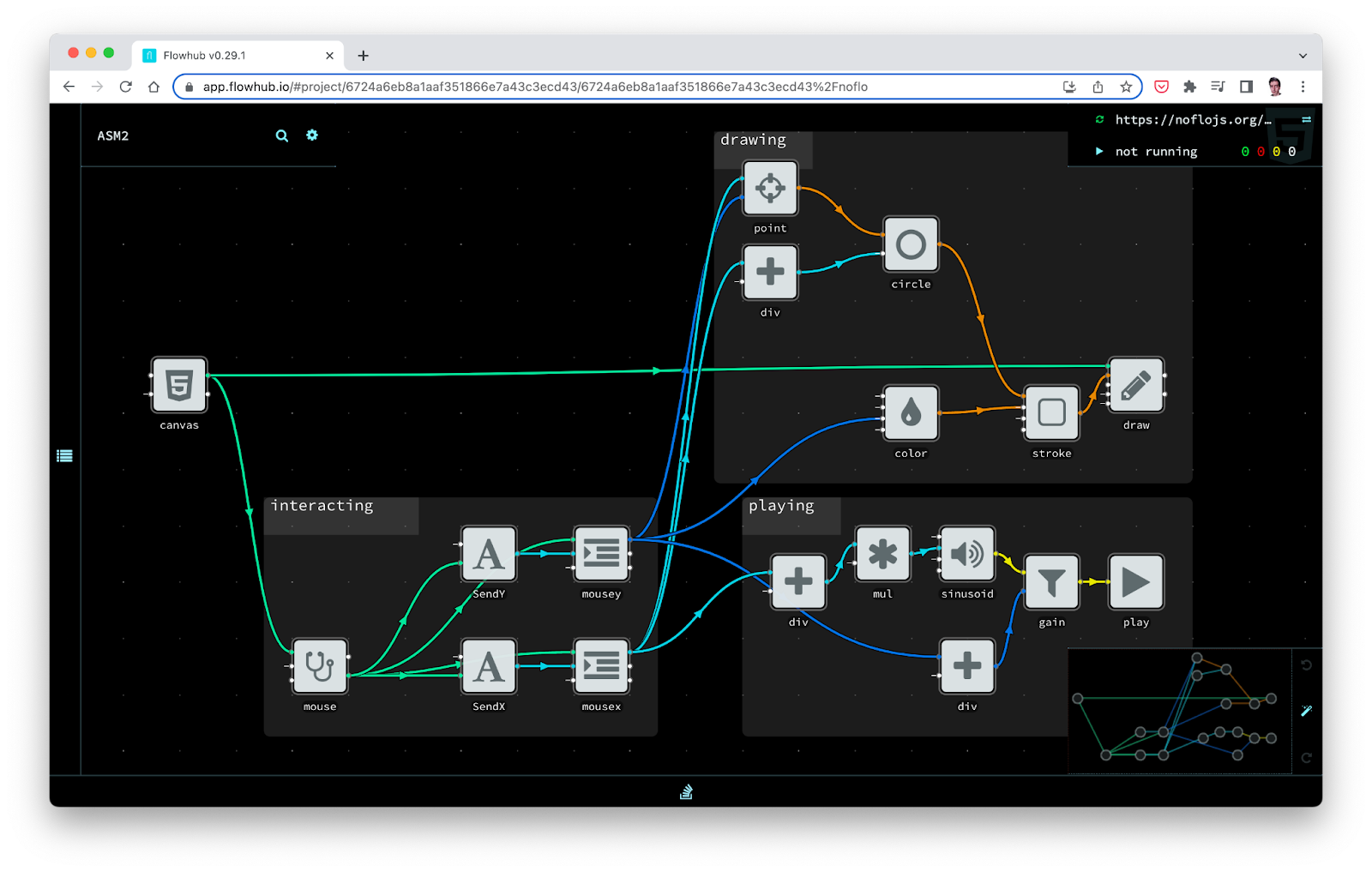
With the advent of NoCode platforms, which use approaches similar to FBP, the concept received a second life. NoCode platforms allow you to create applications without the need for programming, using a graphical interface and drag-and-drop components. This makes creating applications more accessible and convenient for people without a technical background. We can say that the FBP approach inspired such projects as n8n, Make, Enso, and Node-RED. At the same time, they also work with the idea of multistack - let's consider Node-RED and Apache NiFi as brief examples from different industries.
Node-RED is a visual tool that allows you to create data streams based on nodes representing individual functions. Node-RED supports many protocols and technologies such as MQTT, HTTP, WebSocket, TCP, UDP, and is actively used to build systems based on IoT devices and sensor monitoring.
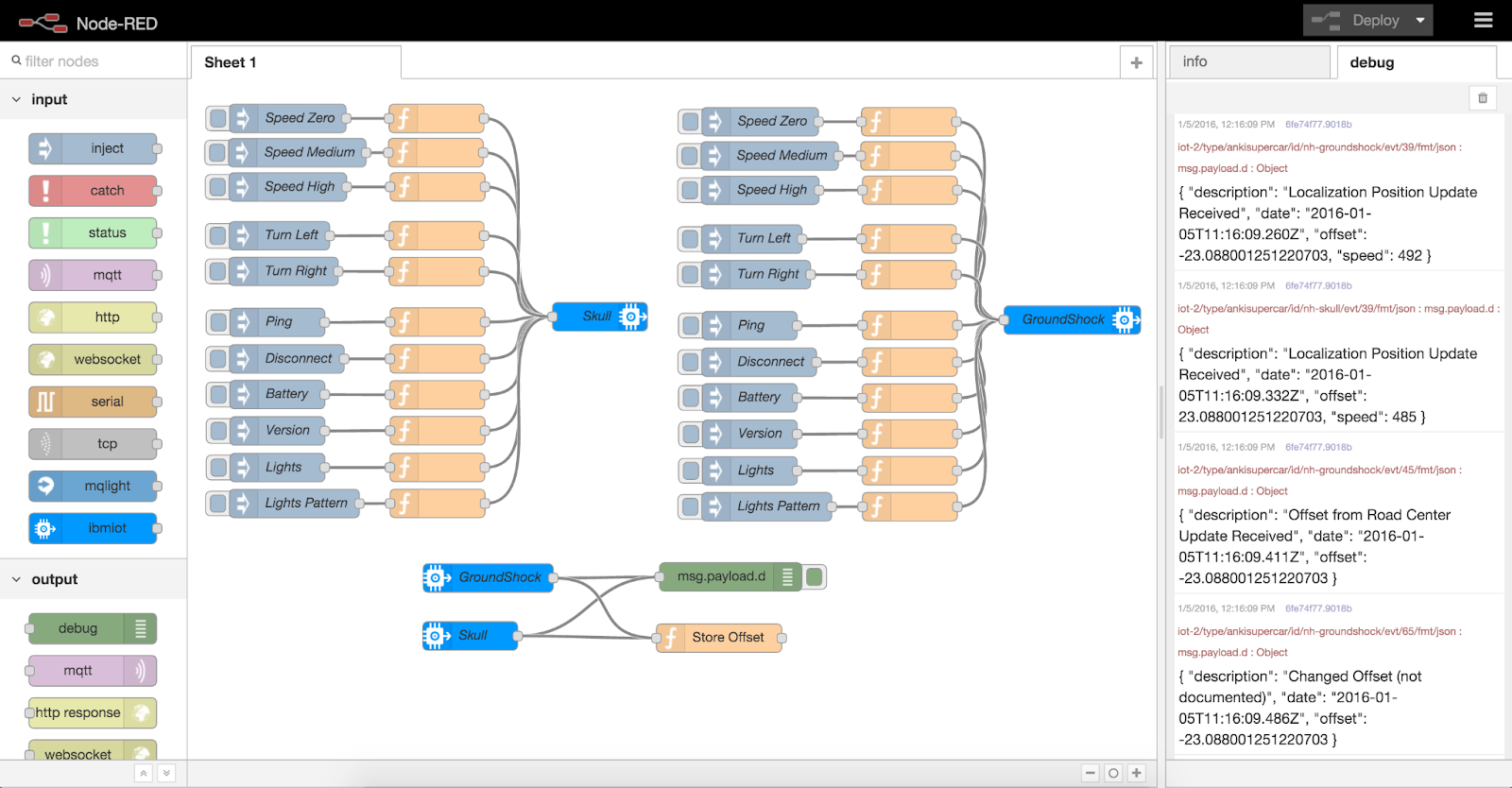
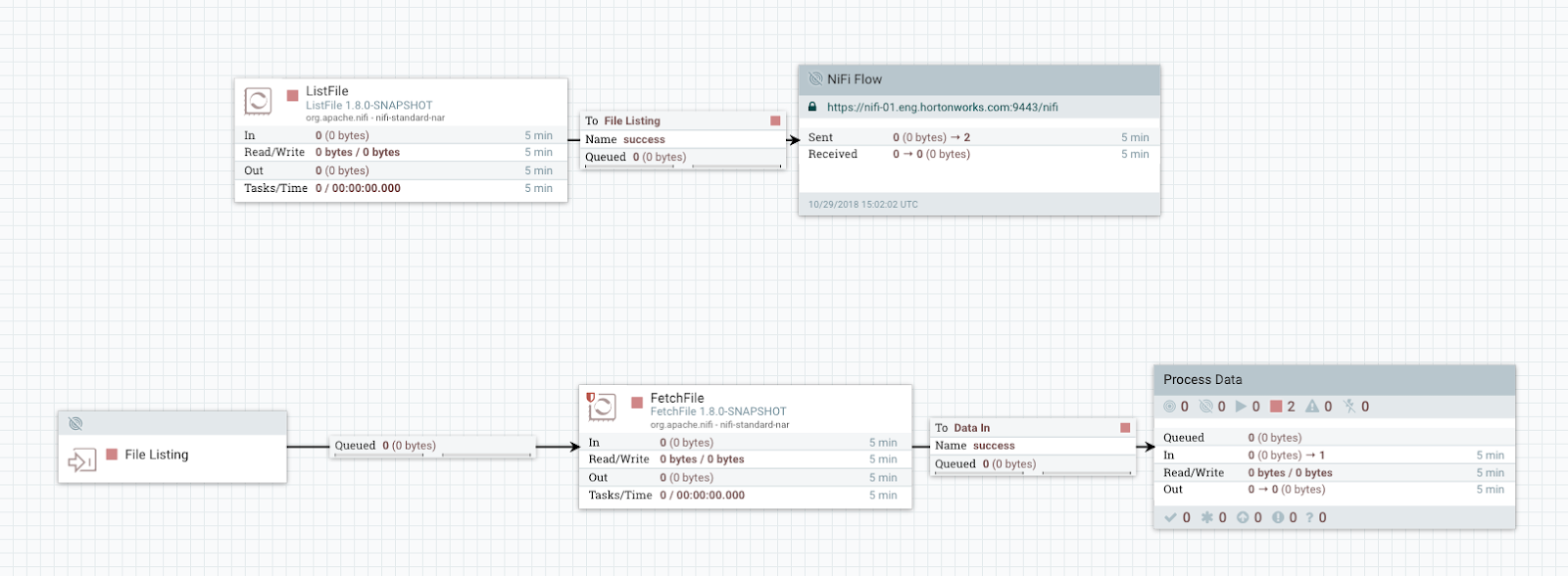
Apache NiFi is a platform for creating, managing, and monitoring data streams. It allows you to create data streams based on a graphical interface with a set of nodes connected to each other. NiFi supports protocols and HTTP, FTP, SMTP, JMS and others. The tool is used to integrate data from different sources, process BigData, monitor and analyze large data streams.
Both examples use the FBP-inspired methodology with function encapsulation in the form of universal blocks. Both applications, due to the unified blocks, allow to work with a wide variety of technologies and protocols.
Conclusion
Despite all the benefits of Flow Based Programming, there are several reasons why the concept has not yet gained much popularity.
- The need for a change in thinking. FBP requires a change in thinking because it is based on the concept of data streams rather than sequences of operations. This requires a change of mindset in developers who are used to other approaches.
- Lack of Tools. Although there are implementations of FBP in various programming languages, there is still a lack of tools and libraries that could facilitate the development process itself in the FBP paradigm.
- The need for additional work. Using FBP requires additional work to design and configure components, which can take more time than with the classical approach.
- Need for training. Using FBP requires learning new concepts and tools, which can be difficult for developers who already have experience with other approaches.
FBP ideas started late and therefore did not receive timely attention and widespread adoption. But now, thanks to the rapid development of NoCode platforms that use FBP ideas, we can say that the concept has finally gained commercial recognition.