EBay scraper: What data can you get using a web-scraper?
EBay scraper software: what to choose? How to scrape prices from eBay.
EBay is one of the largest online stores and auction platforms in the World with over 1.3 billion products – it’s not surprising that eBay scrapers have already been written and are widespread now. By scraping eBay you can get all the details of any goods that are available on the site when you open it with your common browser:
- product title,
- refurbished and pre-owned prices including the cost of shipping to your region,
- previous price and current discount,
- location (country, state, and city),
- product photos,
- product features and description,
- rating and reviews,
- seller information,
- stock availability and number of sales,
- page URLs for product and seller,
- bids information.
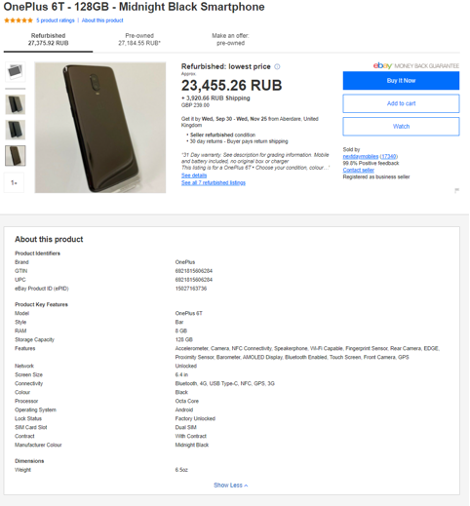
Armed with this data about the goods in your segment you can make conclusions about current market competition and decide if it makes sense for your company to start selling these goods too. EBay is also a unique source of information for redistributors who find the most profitable prices here and re-sell the products at a higher price. Finally, eBay price scraper is in demand for different kinds of marketing researche agencies and price comparing services.
Diving into products features and ratings may give you detailed information about the properties that are significant for customers. Let’s say you are selling smartphones. EBay data mining for smartphone brands, colors, storage capacities, cameras, RAM etc., or any other information relating to the average customer’s choice will point you to the main and most relevant reasons for purchase.
Sellers’ data extraction is useful to get a general idea about your business competitors and their products range and prices. Regular research of sellers is necessary to control your own prices and reach the positive influence on your sales dynamics.
EBay scraper software: what to choose?
It is easy to create an eBay scraper because the site doesn’t use JavaScript or AJAX to execute the query of getting the products list, therefore the number of web scraping eBay software decisions is high, there is definitely a plenty to choose from. Let’s take a quick look at someof them.
- ParseHub – general purpose web scraping software that is suitable for market research, competitor research or finding your next hot bid on eBay. It is equipped with a powerful and simple visual designer combined with a browser where you can state the logic of scraping and select the data you need from the site by request keywords without any programming skills. The result will be given to you as an Excel or JSON file.
- A-Parser – a multi-threaded general purpose parser of search engines, site assessment services, web content, and more. It has ready to use presets for parsing different sites including eBay, but a large number of settings makes the A-Parser interface a little bit confusing. It supports proxies and alternative domain zones for the site.
- Datacol – data parsing software with dozens of modules intended for a large range of tasks. With the help of Datacol you can scrape data from search engines, social networks, news sites, blogs and online stores including eBay. It doesn’t require any programming skills from you. On the one hand, the process of setting up the scraper may seem hard even for advanced users, but on the other hand, you get really flexible functionality. It is especially worth to notice the ability to synchronize data from eBay with your Wordpress site.
- eBay scraper from Scraping Expert – ready to use eBay scraper software for Windows with one screen dashboard to get all the information at a single view. As an input data it accepts search keywords, keyword URLs or lists of specified item numbers (IDs). The output data is returned in a CSV file.
Aother option is to use eBay’s API for data crawling with the SDK for one of the supported programming languages: Java, Python, .NET, JavaScript (Node.js). Many self-written API wrappers are available too, but the main issue here is further maintenance of existing scraper API functions. Selecting the SDK, notice how long ago the last updates took place, otherwise you risk dealing with software or code with no actual support.
Direct web data scraping from eBay isn’t difficult as we mentioned earlier, so it’s not a big deal to write your own scraper. You will need any programming language proficiency with relevant HTTP-client library to obtain data with GET requests and some tools or libraries to parse the HTML structure with CSS-selectors, Regular Expressions or in any other way.
In the next section we will write a short example of eBay scraper python that shows how to get the products prices from the site.
How to scrape prices from eBay?
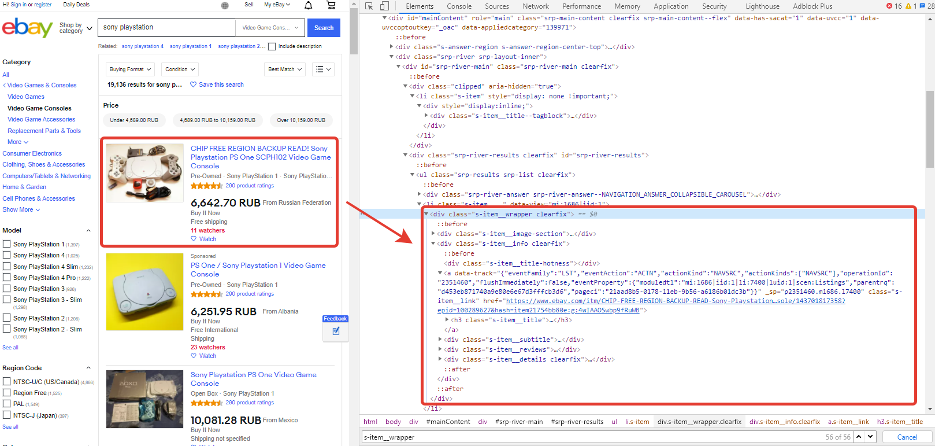
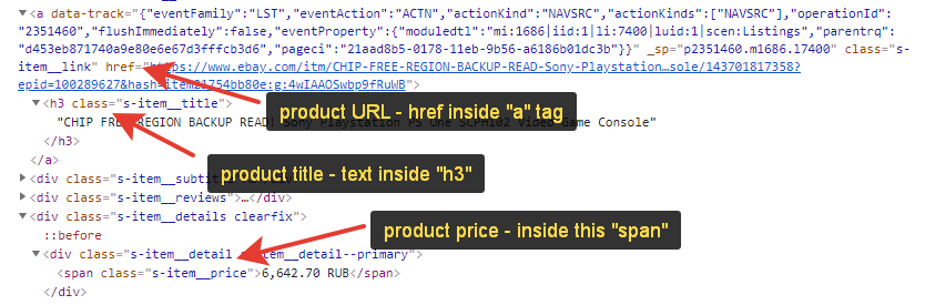
Let’s make some random search on eBay - we will get a list of goods. Then we need to open DevTools in our browser and inspect the structure of HTML relating to the product. We will write out the title, price and URL for each product. It looks pretty easy:
We will need the following Python modules:
import requests
from bs4 import BeautifulSoup as bs
from fake_useragent import UserAgent
All our code will be placed inside this function:
def get_products_prices(query):
# here we will write the result list
result = list()
return result
After we declare the empty list, let’s prepare the query inside URL. Notice that we do not solve the issue of pagination in this example, but you should know that “_pgn=1” parameter is responsible for the page number.
result = list()
# formatting query into URL string (it should be more complex in the real project)
query = query.replace(' ', '+')
# put our query into request URL
url = f'https://www.ebay.com/sch/i.html?_from=R40&' \
f'_trksid=p2380057.m570.l1313&_nkw={query}&_sacat=0&_pgn=1'
Next we will write the headers and make request to our URL. Make sure that we get code 200 response otherwise exit our function with an empty result:
# preparing headers user agent to pretend that we are making requests from real browser
# (not necessary)
ua = UserAgent()
headers = {'user-agent': ua.chrome}
# making request and cheking if we get a valid response
response = requests.get(url, headers=headers)
if response.status_code != 200:
return result
Then let’s make “soup” from HTML as usual:
# parsing response text with Beautifyl Soup
soup = bs(response.text, 'html.parser')
After then we need to get all the div-containers for our products:
# searching for products on the page
items = soup.find_all('div', class_='s-item__wrapper')
And iterate through them:
# iterating through products
for item in items:
line = {
# using selectors to get data (dot inside price is replaced with an empty string)
'title': item.find('h3', class_='s-item__title').text,
'price': item.find('span', class_='s-item__price').text.replace(u'\xa0', ''),
'url': item.find('a', class_='s-item__link').get('href'),
}
# add the product dictionary to the result
result.append(line)
We shouldn’t forget to return the result as we did above in the function and make test.
if __name__ == '__main__':
products = get_products_prices('sony playstation')
for product in products:
print(product)
You will see the list of the elements like this:
{
'title': 'Sony PlayStation 4 Slim 500Gb',
'price': '20850,00 rub.',
'url': 'https://www.ebay.com/itm/Sony-PlayStation-4-Slim-500Gb<…>'
}
The compete Python code is below:
import requests
from bs4 import BeautifulSoup as bs
from fake_useragent import UserAgent
def get_products_prices(query):
# here we will write the result list
result = list()
# formatting query into URL string (it should be more complex in the real project)
query = query.replace(' ', '+')
# put our query into request URL
url = f'https://www.ebay.com/sch/i.html?_from=R40&' \
f'_trksid=p2380057.m570.l1313&_nkw={query}&_sacat=0&_pgn=1'
# preparing headers user agent to pretend that we are making requests from real browser
# (not necessary)
ua = UserAgent()
headers = {'user-agent': ua.chrome}
# making request and cheking if we get a valid response
response = requests.get(url, headers=headers)
if response.status_code != 200:
return result
# parsing response text with Beautifyl Soup
soup = bs(response.text, 'html.parser')
# searching for products on the page
items = soup.find_all('div', class_='s-item__wrapper')
# iterating through products
for item in items:
line = {
# using selectors to get data (dot inside price is replaced with an empty string)
'title': item.find('h3', class_='s-item__title').text,
'price': item.find('span', class_='s-item__price').text.replace(u'\xa0', ''),
'url': item.find('a', class_='s-item__link').get('href'),
}
# add the product dictionary to the result
result.append(line)
return result
if __name__ == '__main__':
products = get_products_prices('sony playstation')
for product in products:
print(product)
Summary
EBay scraping is not difficult, no matter what tools and solutions you choose – all the information is represented in a static HTML structure without dynamically changing elements.